Your Content is Gold: I Turned 3 Years of Blog Posts into an LLM Training
Welcome to Lesson 2 of 12 in our free course series, LLM Twin: Building Your Production-Ready AI Replica. You’ll learn how to use LLMs, vector DVs, and LLMOps best practices to design, train, and deploy a production ready “LLM twin” of yourself. This AI character will write like you, incorporating your style, personality, and voice into an LLM. For a full overview of course objectives and prerequisites, start with Lesson 1.
Lessons
- An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
- Your Content is Gold: I Turned 3 Years of Blog Posts into an LLM Training
- I Replaced 1000 Lines of Polling Code with 50 Lines of CDC Magic
- SOTA Python Streaming Pipelines for Fine-tuning LLMs and RAG — in Real-Time!
- The 4 Advanced RAG Algorithms You Must Know to Implement
- Turning Raw Data Into Fine-Tuning Datasets
- 8B Parameters, 1 GPU, No Problems: The Ultimate LLM Fine-tuning Pipeline
- The Engineer’s Framework for LLM & RAG Evaluation
- Beyond Proof of Concept: Building RAG Systems That Scale
- The Ultimate Prompt Monitoring Pipeline
- [Bonus] Build a scalable RAG ingestion pipeline using 74.3% less code
- [Bonus] Build Multi-Index Advanced RAG Apps
We have data everywhere. Linkedin, Medium, Github, Substack, and many other platforms. To be able to build your Digital Twin, you need data. Not all types of data, but organized, clean, and normalized data. In Lesson 2, we will learn how to think and build a data pipeline by aggregating data from:
- Medium
- Github
- Substack
We will present all our architectural decisions regarding the design of the data collection pipeline for social media data and why separating raw data and feature data is essential.
Note: This Blog Post is the Second Part of a series for the LLM Twin Course. Click here to read the first part!
In Lesson 3, we will present the CDC (change data capture) pattern, a database architecture, and a design for data management systems.
CDC’s primary purpose is to identify and capture changes made to database data, such as insertions, updates, and deletions, which we will detail in Lesson 3.
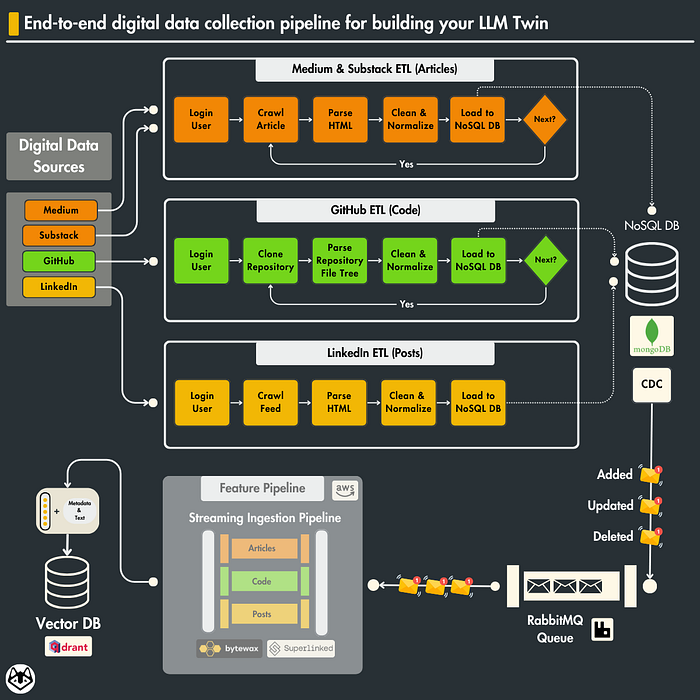
Table of Contents
- What is a data pipeline? The critical point in any AI project.
- Data crawling. How to collect your data?
- How do you store your data?
- Raw data vs. Features data
- Digging into the dispatcher and AWS Lambda
- Run everything and populate your MongoDB data warehouse
1. What is a data pipeline? The critical point in any AI project.
Data is the lifeblood of any successful AI project, and a well-engineered data pipeline is the key to harnessing its power.
This automated system acts as the engine, seamlessly moving data through various stages and transforming it from raw form into actionable insights.
But what exactly is a data pipeline, and why is it so critical?
A data pipeline is a series of automated steps that guide data on a purpose.
It starts with data collection, gathering information from diverse sources, such as LinkedIn, Medium, Substack, Github, etc.
The pipeline then tackles the raw data, performing cleaning and transformation.
This step removes inconsistencies and irrelevant information and transforms the data into a format suitable for analysis and ML models.
But why are data pipelines so crucial in AI projects? Here are some key reasons:
- Efficiency and Automation: Manual data handling is slow and prone to errors. Pipelines automate the process, ensuring speed and accuracy, especially when dealing with massive data volumes.
- Scalability: AI projects often grow in size and complexity. A well-designed pipeline can scale seamlessly, accommodating this growth without compromising performance.
- Quality and Consistency: Pipelines standardize data handling, ensuring consistent and high-quality data throughout the project lifecycle, leading to more reliable AI models.
- Flexibility and Adaptability: The AI landscape is constantly evolving. A robust data pipeline can adapt to changing requirements without a complete rebuild, ensuring long-term value.
Data is the engine of any ML model. If we don’t give it enough importance, the model’s output will be very unexpected.

But how can we transform the raw data into actionable insights?
2. Data crawling. How to collect your data?
The first step in building a database of relevant data is choosing our data sources. In this lesson, we will focus on four sources:
- Medium
- Github
- Substack
Why do we choose 4 data sources? We need complexity and diversity in our data to build a powerful LLM twin. To obtain these characteristics, we will focus on building three collections of data:
- Articles
- Social Media Posts
- Code
For the data crawling module, we will focus on two libraries:
- BeautifulSoup: A Python library for parsing HTML and XML documents. It creates parse trees that help us extract the data quickly, but BeautifulSoup needs to fetch the web page for us. That’s why we need to use it alongside libraries like
requestsorSeleniumwhich can fetch the page for us. - Selenium: A tool for automating web browsers. It’s used here to interact with web pages programmatically (like logging into LinkedIn, navigating through profiles, etc.). Selenium can work with various browsers, but this code configures it to work with Chrome. We created a base crawler class to respect the best software engineering practices.
The BaseAbstractCrawler class in a web crawling context is essential for several key reasons:
- Code Reusability and Efficiency: It contains standard methods and properties used by different scrapers, reducing code duplication and promoting efficient development.
- Simplification and Structure: This base class abstracts complex or repetitive code, allowing derived scraper classes to focus on specific tasks. It enforces a consistent structure across different scrapers.
- Ease of Extension: New types of scrapers can easily extend this base class, making the system adaptable and scalable for future requirements.
- Maintenance and Testing: Updates or fixes to standard functionalities must be made only once in the base class, simplifying maintenance and testing.
import time
from abc import ABC, abstractmethod
from tempfile import mkdtemp
from core.db.documents import BaseDocument
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class BaseCrawler(ABC):
model: type[BaseDocument]
@abstractmethod
def extract(self, link: str, **kwargs) -> None: ...
class BaseAbstractCrawler(BaseCrawler, ABC):
def __init__(self, scroll_limit: int = 5) -> None:
options = webdriver.ChromeOptions()
options.add_argument("--no-sandbox")
options.add_argument("--headless=new")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--log-level=3")
options.add_argument("--disable-popup-blocking")
options.add_argument("--disable-notifications")
options.add_argument("--disable-extensions")
options.add_argument("--disable-background-networking")
options.add_argument("--ignore-certificate-errors")
options.add_argument(f"--user-data-dir={mkdtemp()}")
options.add_argument(f"--data-path={mkdtemp()}")
options.add_argument(f"--disk-cache-dir={mkdtemp()}")
options.add_argument("--remote-debugging-port=9226")
self.set_extra_driver_options(options)
self.scroll_limit = scroll_limit
self.driver = webdriver.Chrome(
options=options,
)
def set_extra_driver_options(self, options: Options) -> None:
pass
def login(self) -> None:
pass
def scroll_page(self) -> None:
"""Scroll through the LinkedIn page based on the scroll limit."""
current_scroll = 0
last_height = self.driver.execute_script("return document.body.scrollHeight")
while True:
self.driver.execute_script(
"window.scrollTo(0, document.body.scrollHeight);"
)
time.sleep(5)
new_height = self.driver.execute_script("return document.body.scrollHeight")
if new_height == last_height or (
self.scroll_limit and current_scroll >= self.scroll_limit
):
break
last_height = new_height
current_scroll += 1 The base classes can be found at data_crawling/crawlers/base.py.
We created separate crawlers for each collection (posts, articles, and repositories), which you can find in the data_crawling/crawlers folder
Every crawler extends the BaseCrawler or BaseAbstractCrawler class, depending on the purpose.
The MediumCrawler, and LinkedinCrawler extend the BaseAbstractCrawler (as they depend on the login and scrolling functionality).
Here is what the MediumCrawler looks like ↓
from aws_lambda_powertools import Logger
from bs4 import BeautifulSoup
from core.db.documents import ArticleDocument
from selenium.webdriver.common.by import By
from crawlers.base import BaseAbstractCrawler
logger = Logger(service="llm-twin-course/crawler")
class MediumCrawler(BaseAbstractCrawler):
model = ArticleDocument
def set_extra_driver_options(self, options) -> None:
options.add_argument(r"--profile-directory=Profile 2")
def extract(self, link: str, **kwargs) -> None:
logger.info(f"Starting scrapping Medium article: {link}")
self.driver.get(link)
self.scroll_page()
soup = BeautifulSoup(self.driver.page_source, "html.parser")
title = soup.find_all("h1", class_="pw-post-title")
subtitle = soup.find_all("h2", class_="pw-subtitle-paragraph")
data = {
"Title": title[0].string if title else None,
"Subtitle": subtitle[0].string if subtitle else None,
"Content": soup.get_text(),
}
logger.info(f"Successfully scraped and saved article: {link}")
self.driver.close()
instance = self.model(
platform="medium", content=data, link=link, author_id=kwargs.get("user")
)
instance.save()
def login(self):
"""Log in to Medium with Google"""
self.driver.get("https://medium.com/m/signin")
self.driver.find_element(By.TAG_NAME, "a").click()For example, the GitHub crawler is a static crawler that doesn’t need a login function, scroll_page function, or driver. It uses only git commands.
The GithubCrawler extends the BaseCrawler class and uses the extract method to retrieve the desired repository.
import os
import shutil
import subprocess
import tempfile
from crawlers.base import BaseCrawler
from documents import RepositoryDocument
class GithubCrawler(BaseCrawler):
model = RepositoryDocument
def __init__(self, ignore=(".git", ".toml", ".lock", ".png")):
super().__init__()
self._ignore = ignore
def extract(self, link: str, **kwargs):
repo_name = link.rstrip("/").split("/")[-1]
local_temp = tempfile.mkdtemp()
try:
os.chdir(local_temp)
subprocess.run(["git", "clone", link])
repo_path = os.path.join(local_temp, os.listdir(local_temp)[0])
tree = {}
for root, dirs, files in os.walk(repo_path):
dir = root.replace(repo_path, "").lstrip("/")
if dir.startswith(self._ignore):
continue
for file in files:
if file.endswith(self._ignore):
continue
file_path = os.path.join(dir, file)
with open(os.path.join(root, file), "r", errors="ignore") as f:
tree[file_path] = f.read().replace(" ", "")
instance = self.model(
name=repo_name, link=link, content=tree, owner_id=kwargs.get("user")
)
instance.save()
except Exception:
raise
finally:
shutil.rmtree(local_temp)3. How do you store your data? An ODM approach
Object Document Mapping (ODM) is a technique that maps between an object model in an application and a document database.
By abstracting database interactions through model classes, it simplifies the process of storing and managing data in a document-oriented database like MongoDB. This approach is particularly beneficial in applications where data structures align well with object-oriented programming paradigms.
The documents.py module serves as a foundational framework for interacting with MongoDB.
Our data modeling centers on creating specific document classes — UserDocument, RepositoryDocument, PostDocument, and ArticleDocument — that mirror the structure of our MongoDB collections.
These classes define the schema for each data type we store, such as users’ details, repository metadata, post content, and article information.
By using these classes, we can ensure that the data inserted into our database is consistent, valid, and easily retrievable for further operations.
import uuid
from typing import List, Optional
from pydantic import UUID4, BaseModel, ConfigDict, Field
from pymongo import errors
import core.logger_utils as logger_utils
from core.db.mongo import connection
from core.errors import ImproperlyConfigured
_database = connection.get_database("twin")
logger = logger_utils.get_logger(__name__)
class BaseDocument(BaseModel):
id: UUID4 = Field(default_factory=uuid.uuid4)
model_config = ConfigDict(from_attributes=True, populate_by_name=True)
@classmethod
def from_mongo(cls, data: dict):
"""Convert "_id" (str object) into "id" (UUID object)."""
if not data:
return data
id = data.pop("_id", None)
return cls(**dict(data, id=id))
def to_mongo(self, **kwargs) -> dict:
"""Convert "id" (UUID object) into "_id" (str object)."""
exclude_unset = kwargs.pop("exclude_unset", False)
by_alias = kwargs.pop("by_alias", True)
parsed = self.model_dump(
exclude_unset=exclude_unset, by_alias=by_alias, **kwargs
)
if "_id" not in parsed and "id" in parsed:
parsed["_id"] = str(parsed.pop("id"))
return parsed
def save(self, **kwargs):
...
@classmethod
def get_or_create(cls, **filter_options) -> Optional[str]:
...
@classmethod
def find(cls, **filter_options):
...
@classmethod
def bulk_insert(cls, documents: List, **kwargs) -> Optional[List[str]]:
...
@classmethod
def _get_collection_name(cls):
if not hasattr(cls, "Settings") or not hasattr(cls.Settings, "name"):
raise ImproperlyConfigured(
"Document should define an Settings configuration class with the name of the collection."
)
return cls.Settings.name
class UserDocument(BaseDocument):
first_name: str
last_name: str
class Settings:
name = "users"
class RepositoryDocument(BaseDocument):
name: str
link: str
content: dict
owner_id: str = Field(alias="owner_id")
class Settings:
name = "repositories"
class PostDocument(BaseDocument):
platform: str
content: dict
author_id: str = Field(alias="author_id")
class Settings:
name = "posts"
class ArticleDocument(BaseDocument):
platform: str
link: str
content: dict
author_id: str = Field(alias="author_id")
class Settings:
name = "articles"In our ODM approach for MongoDB, key CRUD operations are integrated:
- Conversion: The
to_mongomethod transforms model instances into MongoDB-friendly formats. - Inserting: The
savemethod uses PyMongo’sinsert_onefor adding documents, returning MongoDB’s acknowledgment as the inserted ID. - Bulk Operations:
bulk_insertemploysinsert_manyfor adding multiple documents and returning their IDs. - Upserting:
get_or_createeither fetches an existing document or creates a new one, ensuring seamless data updates. - Validation and Transformation: Using Pydantic models, each class ensures data is correctly structured and validated before database entry.
Full code at core/db/documents.py
4. Raw data vs. features data
Now that we understand the critical role of data pipelines in preparing raw data let’s explore how we can transform this data into a usable format for our LLM twin. This is where the concept of features comes into play.
Features are the processed building blocks used to fine-tune your LLM twin.
Imagine you’re teaching someone your writing style. You wouldn’t just hand them all your social media posts! Instead, you might point out your frequent use of specific keywords, the types of topics you write about, or the overall sentiment you convey. Features work similarly for your LLM twin.
Raw data, on the other hand, is the unrefined information collected from various sources. Social media posts might contain emojis, irrelevant links, or even typos. This raw data needs cleaning and transformation before it can be used effectively.
In our data flow, raw data is initially captured and stored in MongoDB, which remains unprocessed.
Then, we process this data to create features — key details we use to teach our LLM twin — and keep these in Qdrant. We do this to keep our raw data intact in case we need it again, while Qdrant holds the ready-to-use features for efficient machine learning.
5. Digging into the dispatcher and AWS Lambda
In this section, we will focus on how to constantly update our database with the most recent data from the 3 data sources.
Before diving into how to build the infrastructure of our data pipeline, I would like to show you how to “think” through the whole process before stepping into the details of AWS.
The first step in doing an infrastructure is to draw a high-level overview of my components.
So, the components of our data pipeline are:
- Linkedin crawler
- Medium crawler
- Github crawler
- CustomArticle crawler
- MongoDB (Data Collector)

Every crawler is a .py file. Since this data pipeline must be constantly updated, we will design a system based on lambda functions, where every AWS Lambda function represents a crawler.
What is an AWS Lambda function in the AWS Environment?
AWS Lambda is a serverless computing service that allows you to run code without provisioning or managing servers. It executes your code only when needed and scales automatically, from a few daily requests to thousands per second.
Here’s how Lambda fits within the AWS environment and what makes it particularly powerful:
- Event-Driven: AWS Lambda is designed to use events as triggers. These events could be changes to data in an Amazon S3 bucket, updates to a DynamoDB table, HTTP requests via Amazon API Gateway, or direct invocation via SDKs from other applications. In the diagram I provided, the events would likely be new or updated content on LinkedIn, Medium, or GitHub.
- Scalable: AWS Lambda can run as many instances of the function as needed to respond to the rate of incoming events. This could mean running dozens or even hundreds of cases of your function in parallel.
- Managed Execution Environment: AWS handles all the administration of the underlying infrastructure, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring, and logging. This allows you to focus on your code.
How can we put the medium crawler on an AWS Lambda function?
We need a handler.
The handler function is the entry point for the AWS Lambda function. In AWS Lambda, the handler function is invoked when an event triggers the Lambda function.
from aws_lambda_powertools import Logger
from aws_lambda_powertools.utilities.typing import LambdaContext
from core import lib
from core.db.documents import UserDocument
from crawlers import CustomArticleCrawler, GithubCrawler, LinkedInCrawler
from dispatcher import CrawlerDispatcher
logger = Logger(service="llm-twin-course/crawler")
_dispatcher = CrawlerDispatcher()
_dispatcher.register("medium", CustomArticleCrawler)
_dispatcher.register("linkedin", LinkedInCrawler)
_dispatcher.register("github", GithubCrawler)
def handler(event, context: LambdaContext | None = None) -> dict[str, Any]:
first_name, last_name = lib.split_user_full_name(event.get("user"))
user_id = UserDocument.get_or_create(first_name=first_name, last_name=last_name)
link = event.get("link")
crawler = _dispatcher.get_crawler(link)
try:
crawler.extract(link=link, user=user_id)
return {"statusCode": 200, "body": "Link processed successfully"}
except Exception as e:
return {"statusCode": 500, "body": f"An error occurred: {str(e)}"}Full code at data_crawling/main.py
Each crawler function is tailored to its data source: fetching posts from LinkedIn, articles from Medium, and repository data from GitHub.

To trigger the lambda function, we have created a python dispatcher which is responsible to manage the crawlers for specific domains.
You can register crawlers for different domains and then use the get_crawler method to get the appropriate crawler for a given URL, defaulting to the CustomArticleCrawler if the domain is not registered.
import re
from aws_lambda_powertools import Logger
from crawlers.base import BaseCrawler
from crawlers.custom_article import CustomArticleCrawler
logger = Logger(service="llm-twin-course/crawler")
class CrawlerDispatcher:
def __init__(self) -> None:
self._crawlers = {}
def register(self, domain: str, crawler: type[BaseCrawler]) -> None:
self._crawlers[r"https://(www\.)?{}.com/*".format(re.escape(domain))] = crawler
def get_crawler(self, url: str) -> BaseCrawler:
for pattern, crawler in self._crawlers.items():
if re.match(pattern, url):
return crawler()
else:
logger.warning(
f"No crawler found for {url}. Defaulting to CustomArticleCrawler."
)
return CustomArticleCrawler()The responsible crawler processes its respective data and then passes it to the MongoDB data warehouse.
→ Full code at data_crawling/dispatcher.py
The MongoDB component acts as a unified data store, collecting and managing the data harvested by the AWS Lambda functions.
This infrastructure is designed for efficient and scalable data extraction, transformation, and loading (ETL) from diverse sources into a single database.
6. Run everything and populate your MongoDB data warehouse
The first step is to spin up your local infrastructure using Docker by running:
make local-start
Now, you can test the crawler that is running locally as a Lambda function by running the following to crawl a test Medium article:
make local-test-medium
Also, you can test it with a GitHub URL:
local-test-github
To populate the MongoDB data warehouse with all our supported links, run the following:
make local-ingest-data
Which will crawl all the links from the data/links.txt file.
Find step-by-step instructions on installing and running the entire course in our INSTALL_AND_USAGE document from the repository.
Conclusion
In this lesson of the LLM Twin course, you’ve learned how to build crawlers for various data sources such as LinkedIn, GitHub, Medium and custom sites.
Also, you’ve learned how to standardize, clean and store the results in a MongoDB.
By leveraging the dispatcher pattern, we have a central point that knows what crawler to use for what particular link.
Ultimately, we showed you how to wrap the dispatcher under the interface expected by AWS Lambda to deploy it to AWS quickly.
In this lesson, we presented how to build a data pipeline and why it’s so essential in an ML project:
In Lesson 3, we will dive deeper into the change data capture (CDC) pattern and explain how it can connect data engineering to the AI world.
🔗 Check out the code on GitHub [1] and support us with a ⭐️
References
[1] Your LLM Twin Course — GitHub Repository (2024), Decoding ML GitHub Organization
Related Articles


