Text Summarization Modeling with ScikitLLM and Comet

Large Language Models (LLMs) are pretty remarkable. These powerful machine-learning models can understand and generate human-like text, creating a natural conversation experience. But they’re not just for chatting — they can also be used to deliver information, generate information like text summarizations, and get valuable suggestions.
Today, we will talk about ScikitLLM or Scikit Large Language Model. ScikitLLM is interesting because it seamlessly integrates LLMs into your traditional Scikit-learn (Sklearn) library. If you’re familiar with machine learning and statistical modeling, you know Sklearn is a powerful tool that provides users with various unsupervised and supervised learning algorithms for building robust machine learning models.
In this post, we’ll take a deep dive into ScikitLLM and explore how you can use it to build text summarization ML models and monitor them all in Comet.
What is ScikitLLM?
Scikit-LLM, described in the official Scikit-LLM GitHub repository, is scikit-learn meets large language models. This means Scikit-LLM brings the power of powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks.
One of the most fascinating aspects of this integration is that you can access various ML algorithms and leverage advanced natural language processing. Something else I found interesting was that this library maintains scikit-learn’s workflow. This means the process is still basically the same: You import your libraries, load your dataset, split your data, train with the fit method, and make predictions using the predict method.
Now, not to bore you with long talk! Let’s get started!
Getting Started with ScikitLLM
To make use of ScikitLLM, we will need to use the pip install command to install ScikitLLM:
pip install scikit-llm
Currently, Scikit-LLM only supports OpenAI, GPT4ALL, Google PaLM 2, and Azure OpenAI.
We will, however, make use of OpenAI. Thus, you will need to set up an OpenAI account. Once done, set up billingand generate an OpenAI API token key for this project.
Then head over to your Colab or Jupyter notebook and run this:
# importing SKLLMConfig
from skllm.config import SKLLMConfig
# Set your OpenAI API key
SKLLMConfig.set_openai_key("*******")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("**ABC**")
Note: ******* represents your API token key, and **ABC** represents your organization I.D.
Text Summarization with ScikitLLM
We will use the Starbucks reviews dataset from Kaggle for the text summarization modeling. This dataset contains information about reviews, ratings, and location data from various Starbucks stores.
To summarize the reviews, we will utilize the GPTSummarizer module of the ScikitLLM library and the GPT-3.5-turbo model from OpenAI. In the GPTSummarizer module, we can use the max_word parameter to set a flexible limit on the number of words each summary produces. I said flexible because the actual length of the generated summary can be longer than the predetermined limit set. After that, we can use the fit_transform method to feed our review to our model. Once done, we can use print to see the summarized reviews.
import comet_ml
import pandas as pd
from comet_ml import Artifact, Experiment
from skllm.preprocessing import GPTSummarizer
# Load your CSV file into a DataFrame
df = pd.read_csv('/content/reviews_data.csv')
# Select a subset of reviews (e.g., the first 50)
X = df["Review"].values[:50]
# Initialize the GPTSummarizer
reviews_summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=10)
# Generate summaries with your model
generated_reviews = reviews_summarizer.fit_transform(X)

You should try running your model on the entire dataset as well. But the execution of this will take some time. To accomplish this, delete the .values[:50] from the code we previously used.
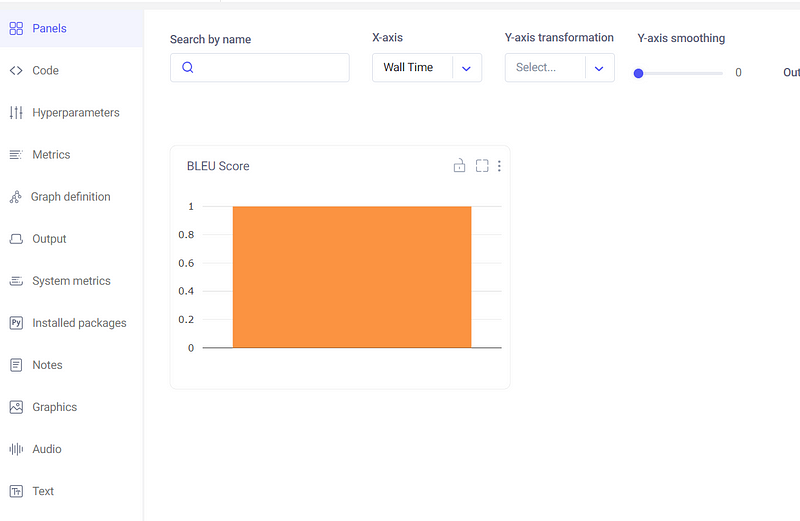
To evaluate how good our model is, we will then compute the BLEU Score. A sentence is compared to one or more reference sentences to determine the BLEU score. The output score ranges from 0 to 1. An output value of 1 indicates that the candidate sentence exactly matches one of the reference sentences. However, since we lacked a reference summary in our data, we are evaluating the generated summaries compared to themselves.
# Join the generated reviews into a single string
reviews_text = "\n".join(generated_reviews)
from nltk.translate.bleu_score import corpus_bleu
bleu_score = corpus_bleu([[summary.split()] for summary in generated_reviews], [summary.split() for summary in generated_reviews])
Running Our Model In Comet
Once done with the modeling, we can log everything in Comet.
To accomplish that, we must first create a project in Comet. Here, we will record all relevant information, including metrics and created reviews, as true. However, if you don’t already have a Comet account, you must create one. You can find the name of your workspace here.
The next step will be to log all our generated reviews from our model as text.
To log in our artifacts, we create an artifact instance by giving it a name, artifact_type, and specifying the file path with artifact.add(). Artifacts here means dataset.
# Initialize Comet
experiment = comet_ml.Experiment(
project_name="Text Summarization",
workspace="bennykillua",
api_key="YOUR KEY",
auto_metric_logging=True,
auto_param_logging=True,
auto_histogram_weight_logging=True,
auto_histogram_gradient_logging=True,
auto_histogram_activation_logging=True,
log_code=True
)
# Log the generated reviews as text
experiment.log_text("Generated Reviews", reviews_text)
comet_ml.login(api_key="YOUR KEY")
# Initialize an Artifact
artifact = Artifact(name="Reviews", artifact_type="dataset")
# Specify the path of the artifact (the dataset file)
artifact.add(r"/content/reviews_data.csv")
# Log the artifact to the experiment (Comet platform)
experiment.log_artifact(artifact)
# Log the BLEU score
experiment.log_metric("BLEU Score", bleu_score)
# Log the model
experiment.log_model(reviews_summarizer, 'model')
# End the experiment
experiment.end()
You can view the logged model on the Comet platform.
Here is the complete code:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"provenance": [],
"authorship_tag": "ABX9TyNQMK9Afs279mqdTEWTKfir",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
},
"language_info": {
"name": "python"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/Bennykillua/db4e3673029d0b933c97bcfe141fdff2/scikit-llm-sklearn-meets-large-language-models.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "markdown",
"source": [
"# Text Summarization Modeling with ScikitLLM and Comet ML\n",
"\n",
"## Install Scikit-LLM\n",
"\n",
"Scikit-LLM integrate powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks.\n",
"\n",
"Check out the [Scikit-LLM offical docs](https://github.com/iryna-kondr/scikit-llm)\n"
],
"metadata": {
"id": "9Kp3v7WGLnn2"
}
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"id": "GWogANz_MQJG",
"colab": {
"base_uri": "https://localhost:8080/"
},
"outputId": "b9a9de35-d2b1-458d-bf12-a2d10ef5e8e4"
},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Requirement already satisfied: scikit-llm in /usr/local/lib/python3.10/dist-packages (0.4.1)\n",
"Requirement already satisfied: scikit-learn>=1.1.0 in /usr/local/lib/python3.10/dist-packages (from scikit-llm) (1.2.2)\n",
"Requirement already satisfied: pandas>=1.5.0 in /usr/local/lib/python3.10/dist-packages (from scikit-llm) (1.5.3)\n",
"Requirement already satisfied: openai>=0.27.9 in /usr/local/lib/python3.10/dist-packages (from scikit-llm) (0.28.0)\n",
"Requirement already satisfied: tqdm>=4.60.0 in /usr/local/lib/python3.10/dist-packages (from scikit-llm) (4.66.1)\n",
"Requirement already satisfied: google-cloud-aiplatform>=1.27.0 in /usr/local/lib/python3.10/dist-packages (from scikit-llm) (1.33.1)\n",
"Requirement already satisfied: google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (2.11.1)\n",
"Requirement already satisfied: proto-plus<2.0.0dev,>=1.22.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (1.22.3)\n",
"Requirement already satisfied: protobuf!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.19.5 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (3.20.3)\n",
"Requirement already satisfied: packaging>=14.3 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (23.1)\n",
"Requirement already satisfied: google-cloud-storage<3.0.0dev,>=1.32.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (2.8.0)\n",
"Requirement already satisfied: google-cloud-bigquery<4.0.0dev,>=1.15.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (3.10.0)\n",
"Requirement already satisfied: google-cloud-resource-manager<3.0.0dev,>=1.3.3 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (1.10.4)\n",
"Requirement already satisfied: shapely<2.0.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-aiplatform>=1.27.0->scikit-llm) (1.8.5.post1)\n",
"Requirement already satisfied: requests>=2.20 in /usr/local/lib/python3.10/dist-packages (from openai>=0.27.9->scikit-llm) (2.31.0)\n",
"Requirement already satisfied: aiohttp in /usr/local/lib/python3.10/dist-packages (from openai>=0.27.9->scikit-llm) (3.8.5)\n",
"Requirement already satisfied: python-dateutil>=2.8.1 in /usr/local/lib/python3.10/dist-packages (from pandas>=1.5.0->scikit-llm) (2.8.2)\n",
"Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas>=1.5.0->scikit-llm) (2023.3.post1)\n",
"Requirement already satisfied: numpy>=1.21.0 in /usr/local/lib/python3.10/dist-packages (from pandas>=1.5.0->scikit-llm) (1.23.5)\n",
"Requirement already satisfied: scipy>=1.3.2 in /usr/local/lib/python3.10/dist-packages (from scikit-learn>=1.1.0->scikit-llm) (1.11.2)\n",
"Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-learn>=1.1.0->scikit-llm) (1.3.2)\n",
"Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn>=1.1.0->scikit-llm) (3.2.0)\n",
"Requirement already satisfied: googleapis-common-protos<2.0.dev0,>=1.56.2 in /usr/local/lib/python3.10/dist-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (1.60.0)\n",
"Requirement already satisfied: google-auth<3.0.dev0,>=2.14.1 in /usr/local/lib/python3.10/dist-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (2.17.3)\n",
"Requirement already satisfied: grpcio<2.0dev,>=1.33.2 in /usr/local/lib/python3.10/dist-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (1.57.0)\n",
"Requirement already satisfied: grpcio-status<2.0.dev0,>=1.33.2 in /usr/local/lib/python3.10/dist-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (1.48.2)\n",
"Requirement already satisfied: google-cloud-core<3.0.0dev,>=1.6.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-bigquery<4.0.0dev,>=1.15.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (2.3.3)\n",
"Requirement already satisfied: google-resumable-media<3.0dev,>=0.6.0 in /usr/local/lib/python3.10/dist-packages (from google-cloud-bigquery<4.0.0dev,>=1.15.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (2.6.0)\n",
"Requirement already satisfied: grpc-google-iam-v1<1.0.0dev,>=0.12.4 in /usr/local/lib/python3.10/dist-packages (from google-cloud-resource-manager<3.0.0dev,>=1.3.3->google-cloud-aiplatform>=1.27.0->scikit-llm) (0.12.6)\n",
"Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.8.1->pandas>=1.5.0->scikit-llm) (1.16.0)\n",
"Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests>=2.20->openai>=0.27.9->scikit-llm) (3.2.0)\n",
"Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests>=2.20->openai>=0.27.9->scikit-llm) (3.4)\n",
"Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests>=2.20->openai>=0.27.9->scikit-llm) (2.0.4)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests>=2.20->openai>=0.27.9->scikit-llm) (2023.7.22)\n",
"Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp->openai>=0.27.9->scikit-llm) (23.1.0)\n",
"Requirement already satisfied: multidict<7.0,>=4.5 in /usr/local/lib/python3.10/dist-packages (from aiohttp->openai>=0.27.9->scikit-llm) (6.0.4)\n",
"Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /usr/local/lib/python3.10/dist-packages (from aiohttp->openai>=0.27.9->scikit-llm) (4.0.3)\n",
"Requirement already satisfied: yarl<2.0,>=1.0 in /usr/local/lib/python3.10/dist-packages (from aiohttp->openai>=0.27.9->scikit-llm) (1.9.2)\n",
"Requirement already satisfied: frozenlist>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from aiohttp->openai>=0.27.9->scikit-llm) (1.4.0)\n",
"Requirement already satisfied: aiosignal>=1.1.2 in /usr/local/lib/python3.10/dist-packages (from aiohttp->openai>=0.27.9->scikit-llm) (1.3.1)\n",
"Requirement already satisfied: cachetools<6.0,>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from google-auth<3.0.dev0,>=2.14.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (5.3.1)\n",
"Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.10/dist-packages (from google-auth<3.0.dev0,>=2.14.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (0.3.0)\n",
"Requirement already satisfied: rsa<5,>=3.1.4 in /usr/local/lib/python3.10/dist-packages (from google-auth<3.0.dev0,>=2.14.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (4.9)\n",
"Requirement already satisfied: google-crc32c<2.0dev,>=1.0 in /usr/local/lib/python3.10/dist-packages (from google-resumable-media<3.0dev,>=0.6.0->google-cloud-bigquery<4.0.0dev,>=1.15.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (1.5.0)\n",
"Requirement already satisfied: pyasn1<0.6.0,>=0.4.6 in /usr/local/lib/python3.10/dist-packages (from pyasn1-modules>=0.2.1->google-auth<3.0.dev0,>=2.14.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.32.0->google-cloud-aiplatform>=1.27.0->scikit-llm) (0.5.0)\n"
]
}
],
"source": [
"pip install scikit-llm"
]
},
{
"cell_type": "code",
"source": [
"# importing SKLLMConfig\n",
"from skllm.config import SKLLMConfig\n",
"\n",
"# Set your OpenAI API key\n",
"SKLLMConfig.set_openai_key(\"*******\")\n",
"\n",
"# Set your OpenAI organization\n",
"\n",
"SKLLMConfig.set_openai_org(\"**ABC**\")"
],
"metadata": {
"id": "g9D6yVFo4rdq"
},
"execution_count": 25,
"outputs": []
},
{
"cell_type": "markdown",
"source": [
"### Mounting our drive"
],
"metadata": {
"id": "KPe07ry0MKMV"
}
},
{
"cell_type": "code",
"source": [
"from google.colab import drive\n",
"drive.mount('/content/drive')"
],
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "bLwZw66Hrazf",
"outputId": "4789c4d3-8324-4a48-af5c-ba99e5dfc6b2"
},
"execution_count": 4,
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
]
}
]
},
{
"cell_type": "markdown",
"source": [
"### Our dataset\n",
"\n",
"We will make use of the [Starbucks reviews dataset](https://www.kaggle.com/datasets/harshalhonde/starbucks-reviews-dataset). This dataset contains information about reviews, rating, and location data from various Starbucks outlets."
],
"metadata": {
"id": "ix1Ws69mMQlZ"
}
},
{
"cell_type": "code",
"source": [
"import pandas as pd\n",
"\n",
"df = pd.read_csv('/content/reviews_data.csv')"
],
"metadata": {
"id": "Krok0k6zMeVt"
},
"execution_count": 5,
"outputs": []
},
{
"cell_type": "code",
"source": [
"df.head(5)"
],
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 293
},
"id": "FITj6vTn8I1V",
"outputId": "dd688b2e-7ce6-4fe9-c936-37b1a83843a5"
},
"execution_count": 6,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
" name location Date Rating \\\n",
"0 Helen Wichita Falls, TX Reviewed Sept. 13, 2023 5.0 \n",
"1 Courtney Apopka, FL Reviewed July 16, 2023 5.0 \n",
"2 Daynelle Cranberry Twp, PA Reviewed July 5, 2023 5.0 \n",
"3 Taylor Seattle, WA Reviewed May 26, 2023 5.0 \n",
"4 Tenessa Gresham, OR Reviewed Jan. 22, 2023 5.0 \n",
"\n",
" Review \\\n",
"0 Amber and LaDonna at the Starbucks on Southwes... \n",
"1 ** at the Starbucks by the fire station on 436... \n",
"2 I just wanted to go out of my way to recognize... \n",
"3 Me and my friend were at Starbucks and my card... \n",
"4 I’m on this kick of drinking 5 cups of warm wa... \n",
"\n",
" Image_Links \n",
"0 ['No Images'] \n",
"1 ['No Images'] \n",
"2 ['https://media.consumeraffairs.com/files/cach... \n",
"3 ['No Images'] \n",
"4 ['https://media.consumeraffairs.com/files/cach... "
],
"text/html": [
"\n",
" <div id=\"df-bd6fdd44-67e9-4e5b-9132-30166cf4137d\" class=\"colab-df-container\">\n",
" <div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>name</th>\n",
" <th>location</th>\n",
" <th>Date</th>\n",
" <th>Rating</th>\n",
" <th>Review</th>\n",
" <th>Image_Links</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>0</th>\n",
" <td>Helen</td>\n",
" <td>Wichita Falls, TX</td>\n",
" <td>Reviewed Sept. 13, 2023</td>\n",
" <td>5.0</td>\n",
" <td>Amber and LaDonna at the Starbucks on Southwes...</td>\n",
" <td>['No Images']</td>\n",
" </tr>\n",
" <tr>\n",
" <th>1</th>\n",
" <td>Courtney</td>\n",
" <td>Apopka, FL</td>\n",
" <td>Reviewed July 16, 2023</td>\n",
" <td>5.0</td>\n",
" <td>** at the Starbucks by the fire station on 436...</td>\n",
" <td>['No Images']</td>\n",
" </tr>\n",
" <tr>\n",
" <th>2</th>\n",
" <td>Daynelle</td>\n",
" <td>Cranberry Twp, PA</td>\n",
" <td>Reviewed July 5, 2023</td>\n",
" <td>5.0</td>\n",
" <td>I just wanted to go out of my way to recognize...</td>\n",
" <td>['https://media.consumeraffairs.com/files/cach...</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3</th>\n",
" <td>Taylor</td>\n",
" <td>Seattle, WA</td>\n",
" <td>Reviewed May 26, 2023</td>\n",
" <td>5.0</td>\n",
" <td>Me and my friend were at Starbucks and my card...</td>\n",
" <td>['No Images']</td>\n",
" </tr>\n",
" <tr>\n",
" <th>4</th>\n",
" <td>Tenessa</td>\n",
" <td>Gresham, OR</td>\n",
" <td>Reviewed Jan. 22, 2023</td>\n",
" <td>5.0</td>\n",
" <td>I’m on this kick of drinking 5 cups of warm wa...</td>\n",
" <td>['https://media.consumeraffairs.com/files/cach...</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"</div>\n",
" <div class=\"colab-df-buttons\">\n",
"\n",
" <div class=\"colab-df-container\">\n",
" <button class=\"colab-df-convert\" onclick=\"convertToInteractive('df-bd6fdd44-67e9-4e5b-9132-30166cf4137d')\"\n",
" title=\"Convert this dataframe to an interactive table.\"\n",
" style=\"display:none;\">\n",
"\n",
" <svg xmlns=\"http://www.w3.org/2000/svg\" height=\"24px\" viewBox=\"0 -960 960 960\">\n",
" <path d=\"M120-120v-720h720v720H120Zm60-500h600v-160H180v160Zm220 220h160v-160H400v160Zm0 220h160v-160H400v160ZM180-400h160v-160H180v160Zm440 0h160v-160H620v160ZM180-180h160v-160H180v160Zm440 0h160v-160H620v160Z\"/>\n",
" </svg>\n",
" </button>\n",
"\n",
" <style>\n",
" .colab-df-container {\n",
" display:flex;\n",
" gap: 12px;\n",
" }\n",
"\n",
" .colab-df-convert {\n",
" background-color: #E8F0FE;\n",
" border: none;\n",
" border-radius: 50%;\n",
" cursor: pointer;\n",
" display: none;\n",
" fill: #1967D2;\n",
" height: 32px;\n",
" padding: 0 0 0 0;\n",
" width: 32px;\n",
" }\n",
"\n",
" .colab-df-convert:hover {\n",
" background-color: #E2EBFA;\n",
" box-shadow: 0px 1px 2px rgba(60, 64, 67, 0.3), 0px 1px 3px 1px rgba(60, 64, 67, 0.15);\n",
" fill: #174EA6;\n",
" }\n",
"\n",
" .colab-df-buttons div {\n",
" margin-bottom: 4px;\n",
" }\n",
"\n",
" [theme=dark] .colab-df-convert {\n",
" background-color: #3B4455;\n",
" fill: #D2E3FC;\n",
" }\n",
"\n",
" [theme=dark] .colab-df-convert:hover {\n",
" background-color: #434B5C;\n",
" box-shadow: 0px 1px 3px 1px rgba(0, 0, 0, 0.15);\n",
" filter: drop-shadow(0px 1px 2px rgba(0, 0, 0, 0.3));\n",
" fill: #FFFFFF;\n",
" }\n",
" </style>\n",
"\n",
" <script>\n",
" const buttonEl =\n",
" document.querySelector('#df-bd6fdd44-67e9-4e5b-9132-30166cf4137d button.colab-df-convert');\n",
" buttonEl.style.display =\n",
" google.colab.kernel.accessAllowed ? 'block' : 'none';\n",
"\n",
" async function convertToInteractive(key) {\n",
" const element = document.querySelector('#df-bd6fdd44-67e9-4e5b-9132-30166cf4137d');\n",
" const dataTable =\n",
" await google.colab.kernel.invokeFunction('convertToInteractive',\n",
" [key], {});\n",
" if (!dataTable) return;\n",
"\n",
" const docLinkHtml = 'Like what you see? Visit the ' +\n",
" '<a target=\"_blank\" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'\n",
" + ' to learn more about interactive tables.';\n",
" element.innerHTML = '';\n",
" dataTable['output_type'] = 'display_data';\n",
" await google.colab.output.renderOutput(dataTable, element);\n",
" const docLink = document.createElement('div');\n",
" docLink.innerHTML = docLinkHtml;\n",
" element.appendChild(docLink);\n",
" }\n",
" </script>\n",
" </div>\n",
"\n",
"\n",
"<div id=\"df-54455e1a-8aed-4f88-b643-16b4094707e1\">\n",
" <button class=\"colab-df-quickchart\" onclick=\"quickchart('df-54455e1a-8aed-4f88-b643-16b4094707e1')\"\n",
" title=\"Suggest charts.\"\n",
" style=\"display:none;\">\n",
"\n",
"<svg xmlns=\"http://www.w3.org/2000/svg\" height=\"24px\"viewBox=\"0 0 24 24\"\n",
" width=\"24px\">\n",
" <g>\n",
" <path d=\"M19 3H5c-1.1 0-2 .9-2 2v14c0 1.1.9 2 2 2h14c1.1 0 2-.9 2-2V5c0-1.1-.9-2-2-2zM9 17H7v-7h2v7zm4 0h-2V7h2v10zm4 0h-2v-4h2v4z\"/>\n",
" </g>\n",
"</svg>\n",
" </button>\n",
"\n",
"<style>\n",
" .colab-df-quickchart {\n",
" --bg-color: #E8F0FE;\n",
" --fill-color: #1967D2;\n",
" --hover-bg-color: #E2EBFA;\n",
" --hover-fill-color: #174EA6;\n",
" --disabled-fill-color: #AAA;\n",
" --disabled-bg-color: #DDD;\n",
" }\n",
"\n",
" [theme=dark] .colab-df-quickchart {\n",
" --bg-color: #3B4455;\n",
" --fill-color: #D2E3FC;\n",
" --hover-bg-color: #434B5C;\n",
" --hover-fill-color: #FFFFFF;\n",
" --disabled-bg-color: #3B4455;\n",
" --disabled-fill-color: #666;\n",
" }\n",
"\n",
" .colab-df-quickchart {\n",
" background-color: var(--bg-color);\n",
" border: none;\n",
" border-radius: 50%;\n",
" cursor: pointer;\n",
" display: none;\n",
" fill: var(--fill-color);\n",
" height: 32px;\n",
" padding: 0;\n",
" width: 32px;\n",
" }\n",
"\n",
" .colab-df-quickchart:hover {\n",
" background-color: var(--hover-bg-color);\n",
" box-shadow: 0 1px 2px rgba(60, 64, 67, 0.3), 0 1px 3px 1px rgba(60, 64, 67, 0.15);\n",
" fill: var(--button-hover-fill-color);\n",
" }\n",
"\n",
" .colab-df-quickchart-complete:disabled,\n",
" .colab-df-quickchart-complete:disabled:hover {\n",
" background-color: var(--disabled-bg-color);\n",
" fill: var(--disabled-fill-color);\n",
" box-shadow: none;\n",
" }\n",
"\n",
" .colab-df-spinner {\n",
" border: 2px solid var(--fill-color);\n",
" border-color: transparent;\n",
" border-bottom-color: var(--fill-color);\n",
" animation:\n",
" spin 1s steps(1) infinite;\n",
" }\n",
"\n",
" @keyframes spin {\n",
" 0% {\n",
" border-color: transparent;\n",
" border-bottom-color: var(--fill-color);\n",
" border-left-color: var(--fill-color);\n",
" }\n",
" 20% {\n",
" border-color: transparent;\n",
" border-left-color: var(--fill-color);\n",
" border-top-color: var(--fill-color);\n",
" }\n",
" 30% {\n",
" border-color: transparent;\n",
" border-left-color: var(--fill-color);\n",
" border-top-color: var(--fill-color);\n",
" border-right-color: var(--fill-color);\n",
" }\n",
" 40% {\n",
" border-color: transparent;\n",
" border-right-color: var(--fill-color);\n",
" border-top-color: var(--fill-color);\n",
" }\n",
" 60% {\n",
" border-color: transparent;\n",
" border-right-color: var(--fill-color);\n",
" }\n",
" 80% {\n",
" border-color: transparent;\n",
" border-right-color: var(--fill-color);\n",
" border-bottom-color: var(--fill-color);\n",
" }\n",
" 90% {\n",
" border-color: transparent;\n",
" border-bottom-color: var(--fill-color);\n",
" }\n",
" }\n",
"</style>\n",
"\n",
" <script>\n",
" async function quickchart(key) {\n",
" const quickchartButtonEl =\n",
" document.querySelector('#' + key + ' button');\n",
" quickchartButtonEl.disabled = true; // To prevent multiple clicks.\n",
" quickchartButtonEl.classList.add('colab-df-spinner');\n",
" try {\n",
" const charts = await google.colab.kernel.invokeFunction(\n",
" 'suggestCharts', [key], {});\n",
" } catch (error) {\n",
" console.error('Error during call to suggestCharts:', error);\n",
" }\n",
" quickchartButtonEl.classList.remove('colab-df-spinner');\n",
" quickchartButtonEl.classList.add('colab-df-quickchart-complete');\n",
" }\n",
" (() => {\n",
" let quickchartButtonEl =\n",
" document.querySelector('#df-54455e1a-8aed-4f88-b643-16b4094707e1 button');\n",
" quickchartButtonEl.style.display =\n",
" google.colab.kernel.accessAllowed ? 'block' : 'none';\n",
" })();\n",
" </script>\n",
"</div>\n",
" </div>\n",
" </div>\n"
]
},
"metadata": {},
"execution_count": 6
}
]
},
{
"cell_type": "markdown",
"source": [
"## Text Summarization"
],
"metadata": {
"id": "aKjN6YB878_z"
}
},
{
"cell_type": "code",
"source": [
"!pip install comet_ml"
],
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "zWEwZQdp8mYH",
"outputId": "322d7d38-ba74-4131-c475-c123d3a5c6d0"
},
"execution_count": 8,
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Requirement already satisfied: comet_ml in /usr/local/lib/python3.10/dist-packages (3.33.10)\n",
"Requirement already satisfied: jsonschema!=3.1.0,>=2.6.0 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (4.19.0)\n",
"Requirement already satisfied: psutil>=5.6.3 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (5.9.5)\n",
"Requirement already satisfied: python-box<7.0.0 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (6.1.0)\n",
"Requirement already satisfied: requests-toolbelt>=0.8.0 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (1.0.0)\n",
"Requirement already satisfied: requests>=2.18.4 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (2.31.0)\n",
"Requirement already satisfied: semantic-version>=2.8.0 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (2.10.0)\n",
"Requirement already satisfied: sentry-sdk>=1.1.0 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (1.31.0)\n",
"Requirement already satisfied: simplejson in /usr/local/lib/python3.10/dist-packages (from comet_ml) (3.19.1)\n",
"Requirement already satisfied: six in /usr/local/lib/python3.10/dist-packages (from comet_ml) (1.16.0)\n",
"Requirement already satisfied: urllib3>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (2.0.4)\n",
"Requirement already satisfied: websocket-client<1.4.0,>=0.55.0 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (1.3.3)\n",
"Requirement already satisfied: wrapt>=1.11.2 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (1.15.0)\n",
"Requirement already satisfied: wurlitzer>=1.0.2 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (3.0.3)\n",
"Requirement already satisfied: everett[ini]<3.2.0,>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (3.1.0)\n",
"Requirement already satisfied: dulwich!=0.20.33,>=0.20.6 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (0.21.6)\n",
"Requirement already satisfied: rich>=13.3.2 in /usr/local/lib/python3.10/dist-packages (from comet_ml) (13.5.2)\n",
"Requirement already satisfied: configobj in /usr/local/lib/python3.10/dist-packages (from everett[ini]<3.2.0,>=1.0.1->comet_ml) (5.0.8)\n",
"Requirement already satisfied: attrs>=22.2.0 in /usr/local/lib/python3.10/dist-packages (from jsonschema!=3.1.0,>=2.6.0->comet_ml) (23.1.0)\n",
"Requirement already satisfied: jsonschema-specifications>=2023.03.6 in /usr/local/lib/python3.10/dist-packages (from jsonschema!=3.1.0,>=2.6.0->comet_ml) (2023.7.1)\n",
"Requirement already satisfied: referencing>=0.28.4 in /usr/local/lib/python3.10/dist-packages (from jsonschema!=3.1.0,>=2.6.0->comet_ml) (0.30.2)\n",
"Requirement already satisfied: rpds-py>=0.7.1 in /usr/local/lib/python3.10/dist-packages (from jsonschema!=3.1.0,>=2.6.0->comet_ml) (0.10.2)\n",
"Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests>=2.18.4->comet_ml) (3.2.0)\n",
"Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests>=2.18.4->comet_ml) (3.4)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests>=2.18.4->comet_ml) (2023.7.22)\n",
"Requirement already satisfied: markdown-it-py>=2.2.0 in /usr/local/lib/python3.10/dist-packages (from rich>=13.3.2->comet_ml) (3.0.0)\n",
"Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/dist-packages (from rich>=13.3.2->comet_ml) (2.16.1)\n",
"Requirement already satisfied: mdurl~=0.1 in /usr/local/lib/python3.10/dist-packages (from markdown-it-py>=2.2.0->rich>=13.3.2->comet_ml) (0.1.2)\n"
]
}
]
},
{
"cell_type": "code",
"source": [
"import comet_ml\n",
"import pandas as pd\n",
"from comet_ml import Artifact, Experiment\n",
"from skllm.preprocessing import GPTSummarizer\n",
"\n",
"# Load your CSV file into a DataFrame\n",
"df = pd.read_csv('/content/reviews_data.csv')\n",
"\n",
"# Select a subset of reviews (e.g., the first 50)\n",
"X = df[\"Review\"].values[:50]\n",
"\n",
"# Initialize the GPTSummarizer\n",
"reviews_summarizer = GPTSummarizer(openai_model=\"gpt-3.5-turbo\", max_words=10)\n",
"\n",
"# Generate summaries with your model\n",
"generated_reviews = reviews_summarizer.fit_transform(X)\n"
],
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "B14j45F2zJJm",
"outputId": "80d72ab1-2ddc-42a4-baf1-316a6b41375b"
},
"execution_count": 12,
"outputs": [
{
"output_type": "stream",
"name": "stderr",
"text": [
"100%|██████████| 50/50 [00:47<00:00, 1.05it/s]\n"
]
}
]
},
{
"cell_type": "code",
"source": [
"print(generated_reviews)"
],
"metadata": {
"id": "Gxah5ShjJbYu",
"colab": {
"base_uri": "https://localhost:8080/"
},
"outputId": "c19a2ba4-7c62-4192-ed23-a28569bedeb8"
},
"execution_count": 18,
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"['Starbucks employees at Southwest Parkway are friendly and efficient.'\n",
" 'Starbucks barista in Altamonte Springs made perfect drink, great customer service.'\n",
" 'Starbucks employee Billy made order quickly and with a smile.'\n",
" 'Kind worker at Starbucks paid for drinks when card failed.'\n",
" 'Drinking 5 cups of warm water, Starbucks gives free hot water.'\n",
" 'Order mistakes, uncomfortable encounter, possible racism against stepmom.'\n",
" 'Starbucks coffee tastes like dirt from a garbage dump.'\n",
" 'Starbucks launched new fall items but quickly ran out.'\n",
" 'Ordered wrong drink size, upset about paying $5 for it.'\n",
" 'Unpleasant experience at Smythe St. Superstore, considering selling elsewhere.'\n",
" 'Starbucks canceled my reward cards, played games, and avoided responding.'\n",
" 'Starbucks often runs out of strawberries for Strawberry Refreshers.'\n",
" 'Customer service insulted me, closed account due to low quality.'\n",
" 'Starbucks failed to honor birthday reward, causing frustration for customer.'\n",
" 'No purchase credit or stars received despite reporting the issue.'\n",
" \"Mother sent $15 gift card, Walgreens won't replace, Starbucks unhelpful.\"\n",
" 'Coffee spilled due to faulty lid, causing damage and inconvenience.'\n",
" \"Long wait time and understaffed, won't return to this location.\"\n",
" \"Starbucks ignores customer's request for assistance with rewards points.\"\n",
" 'Starbucks Como Lake: bad service, long wait, confused orders.'\n",
" 'Starbucks sold disappointing breakfast sandwiches that did not match the picture.'\n",
" 'Unhappy customer wants refund for overcharged Starbucks drink.'\n",
" 'Received invalid Starbucks gift cards twice, suspecting a scam.'\n",
" 'Starbucks fails to address lid issue despite customer complaints.'\n",
" \"Starbucks' Covid restrictions and coffee policy are criticized.\"\n",
" 'Bad service and bad coffee at town east Starbucks.'\n",
" 'Starbucks has small tables, making it uncomfortable for customers.'\n",
" 'Chemical odors made me gag, Starbucks spelled my name wrong.'\n",
" \"Starbucks' unhealthy drinks and increased loyalty points made me quit.\"\n",
" 'Starbucks served a drink with a cleaning rag in it.'\n",
" 'Starbucks refuses to resolve account blockage and refund substantial balance.'\n",
" 'Starbucks is ungrateful to employees, rewards program is unfair.'\n",
" 'Starbucks increases stars needed for free drink, prompting dissatisfaction.'\n",
" 'Starbucks provided poor customer service, resulting in a 10 cent refund.'\n",
" 'Starbucks inside Food City has poor logistics and limited options.'\n",
" 'Coffee not good, many other options available.'\n",
" \"Company's deceitful ways, weak coffee, pressured tipping, lost customer.\"\n",
" 'Lakeport Commons in Sioux City always out of items, unreliable mobile ordering.'\n",
" 'Starbucks app failed to refund money for broken drink.'\n",
" \"Company doesn't help customers with mobile account issues, poor customer service.\"\n",
" 'Person has a bad experience at Starbucks drive-thru in Portland.'\n",
" 'Bad service at Starbucks with an old man serving coffee.'\n",
" 'Starbucks closed outlets, lost loyal customer after 20 years.'\n",
" 'Starbucks ad for free coffee on Veterans Day was a lie.'\n",
" \"Starbucks refuses diabetic's request for unsweetened beverage during holidays.\"\n",
" 'Starbucks refused free coffee to veterans on Veterans Day.'\n",
" 'Frequent lid issues at Green Bay Starbucks, spilled drink on floor.'\n",
" 'Unprofessional and rude manager at Tilton Starbucks, unacceptable customer service.'\n",
" 'Starbucks on Sunset is great, but not the new one on Elms Springs.'\n",
" 'Starbucks removes electrical outlets, angers loyal customers.']\n"
]
}
]
},
{
"cell_type": "code",
"source": [
"# Join the generated reviews into a single string\n",
"reviews_text = \"\\n\".join(generated_reviews)\n",
"\n",
"from nltk.translate.bleu_score import corpus_bleu\n",
"\n",
"bleu_score = corpus_bleu([[summary.split()] for summary in generated_reviews], [summary.split() for summary in generated_reviews])"
],
"metadata": {
"id": "UqUzgppRB3xr"
},
"execution_count": 21,
"outputs": []
},
{
"cell_type": "code",
"source": [
"# Initialize Comet\n",
"experiment = comet_ml.Experiment(\n",
" project_name=\"Text Summarization\",\n",
" workspace=\"bennykillua\",\n",
" api_key=\"YOUR KEY\",\n",
" auto_metric_logging=True,\n",
" auto_param_logging=True,\n",
" auto_histogram_weight_logging=True,\n",
" auto_histogram_gradient_logging=True,\n",
" auto_histogram_activation_logging=True,\n",
" log_code=True\n",
")\n",
"\n",
"# Log the generated reviews as text\n",
"experiment.log_text(\"Generated Reviews\", reviews_text)\n",
"\n",
"comet_ml.login(api_key=\"YOUR KEY\")\n",
"\n",
"# Initialize an Artifact\n",
"artifact = Artifact(name=\"Reviews\", artifact_type=\"dataset\")\n",
"\n",
"# Specify the path of the artifact (the dataset file)\n",
"artifact.add(r\"/content/reviews_data.csv\")\n",
"\n",
"# Log the artifact to the experiment (Comet platform)\n",
"experiment.log_artifact(artifact)\n",
"\n",
"# Log the BLEU score\n",
"experiment.log_metric(\"BLEU Score\", bleu_score)\n",
"\n",
"# Log the model\n",
"experiment.log_model(reviews_summarizer, 'model')\n",
"\n",
"# End the experiment\n",
"experiment.end()"
],
"metadata": {
"id": "FS8aVQ3VJ2fB"
},
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"source": [
"# You can view the logged model on the [Comet platform](https://www.comet.com/bennykillua/text-summarization/view/new/panels)"
],
"metadata": {
"id": "RF_-2K-H1XWx"
}
},
{
"cell_type": "code",
"source": [],
"metadata": {
"id": "Y0rrgFRLLYaj"
},
"execution_count": null,
"outputs": []
}
]
}
Conclusion
Integrating Large Language Models with scikit-learn through the SKLLM library allows us to leverage advanced language understanding for various machine learning algorithms. Furthermore, by leveraging Comet, you have a user-friendly interface to track and optimize your hyperparameters and collaborate with other data scientists.
P.S. If you prefer to learn by code, check out this Github gist, which hosts the code snippets. Also, do check out the logged model on the Comet platform.
Related Articles