OpenAI Evals: Log Datasets & Evaluate LLM Performance with Opik

OpenAI’s Python API is quickly becoming one of the most-downloaded Python packages. With an easy-to-use SDK and access to a reliable hardware infrastructure, OpenAI’s Python API is widely considered one of the best tools for developers working on LLM-powered applications. Whether you are building a chatbot, a summarization tool, a machine translation system or a sentiment classifier, OpenAI’s Python API makes it easy to start prototyping.
There is a famous saying by Lord Kelvin: “If you can’t measure it, you can’t improve it.” Building a robust LLM-powered application requires a combination of rigorous experimentation and constant LLM evaluations. Developers are continuously iterating on their prompts so that their applications achieve more desirable outputs from the LLMs they are calling. Simultaneously, developers need a way to quantify the quality of their LLM responses via scoring and annotation processes in order to see what is and isn’t working.
Some of these processes require manual effort, like a human spot-checking a set of LLM responses and leaving notes or scores that describe their accuracy or desirability. To improve efficiency at scale, automated scoring methods can be combined with human feedback. Simple deterministic functions can evaluate for specific requirements. (For example, in a use case that requires responses in JSON from the LLM, a function could evaluate whether each response contains valid JSON, leaving a score of 1 for yes and 0 for no.) A secondary LLM (LLM-as-a-judge) can also be used to score more complex qualities like factuality, answer relevance, and context precision.
Opik, by Comet, is an LLM evaluation platform that developers rely on in both development and production to measure the performance of their LLMs using the techniques described above, and more. With the ability to track LLM inputs, outputs and any related metadata, Opik serves as a single system of record for your prompt engineering work. Opik also allows you to run eval experiments so you can quantitatively compare your LLM responses to see which prompt templates, models, and hyper-parameters produce the best results.
The best part? Opik has a native integration with OpenAI, meaning with just a couple of lines of code you can get out-of-box logging of all your OpenAI interactions to the Opik platform.
Start Logging OpenAI Datasets
Opik is completely open-source. You can choose to self-host it by following the instructions listed here, or you can sign up for an account on our hosted version.
To install the Opik SDK in your python virtual environment, run the following command:
pip install opik
Below is an example of how easy it is to set up logging with Opik.
Simply use our track_openai wrapper and Opik will automatically log the input, output, and metadata and render it in UI.
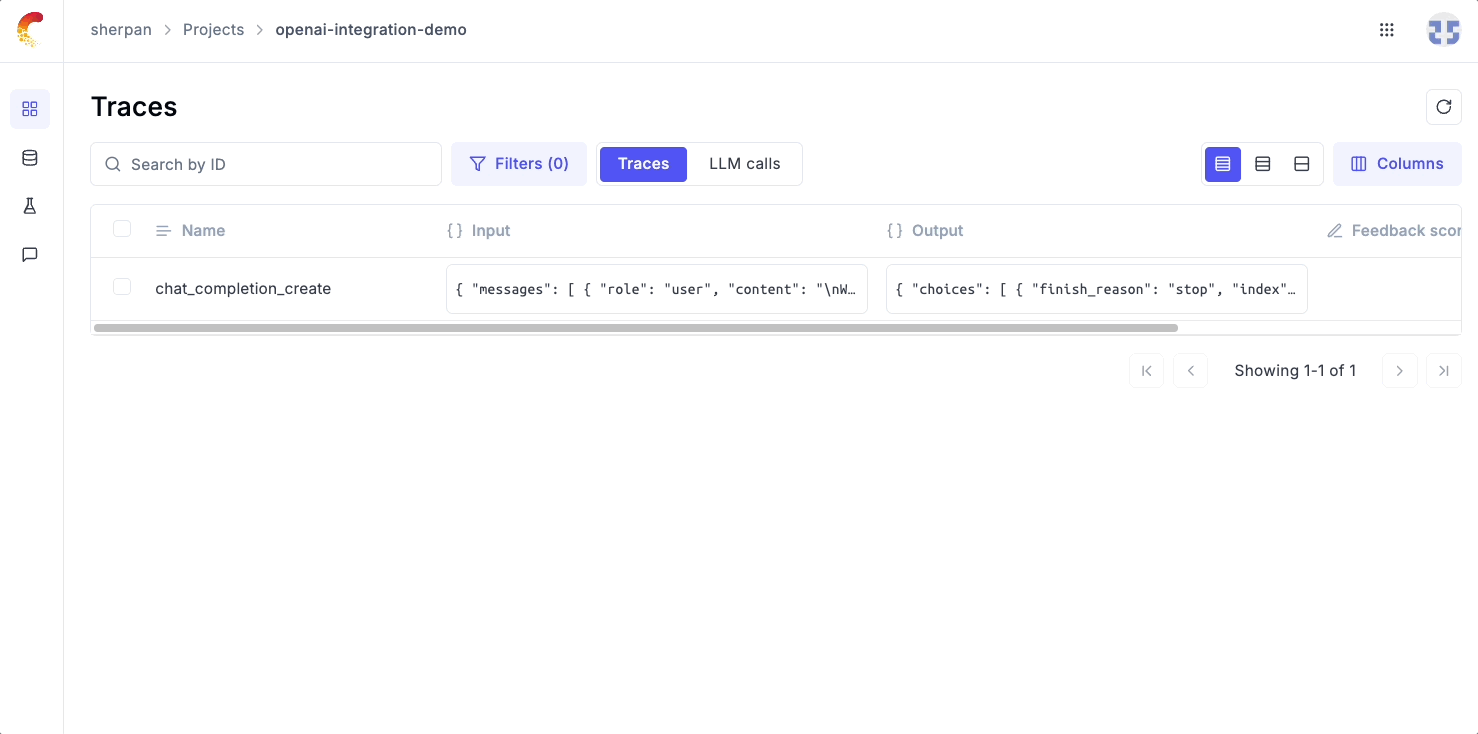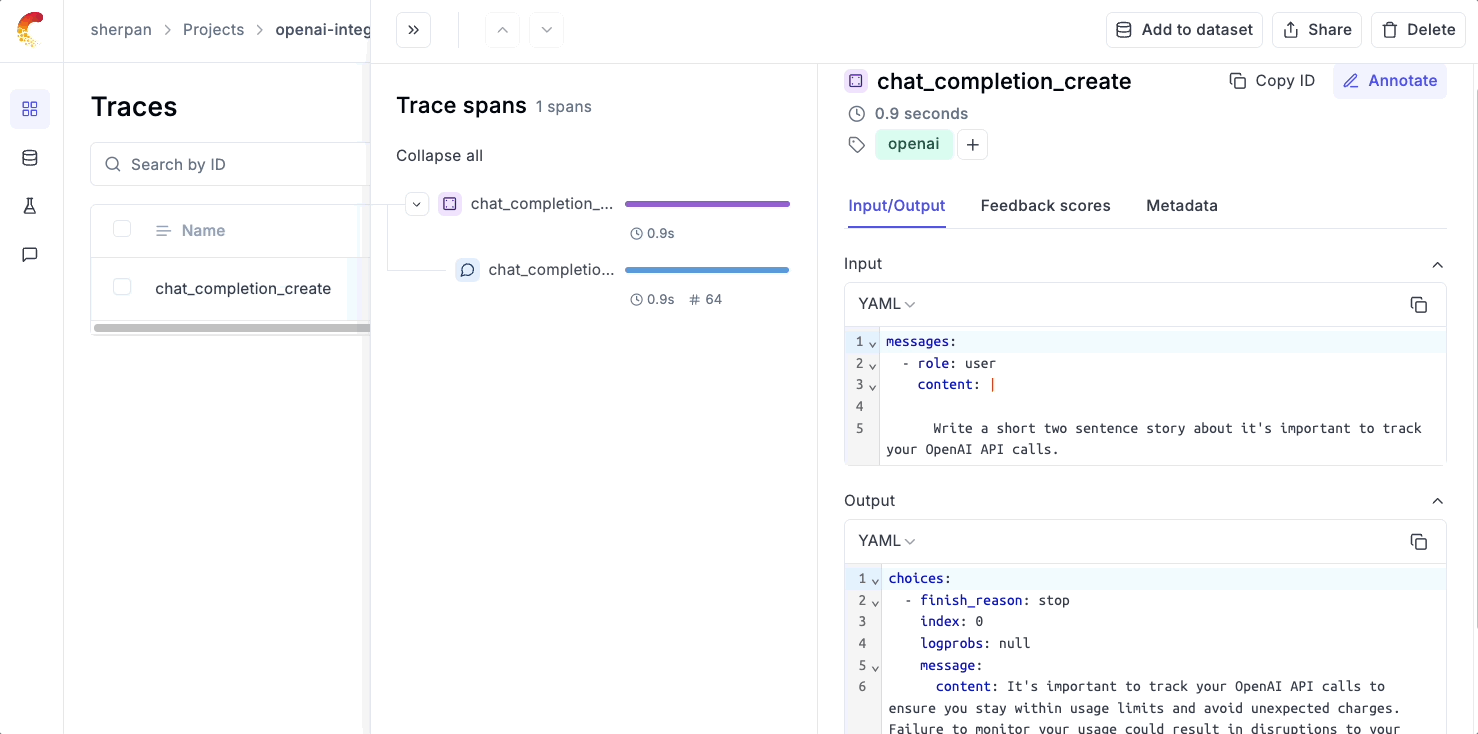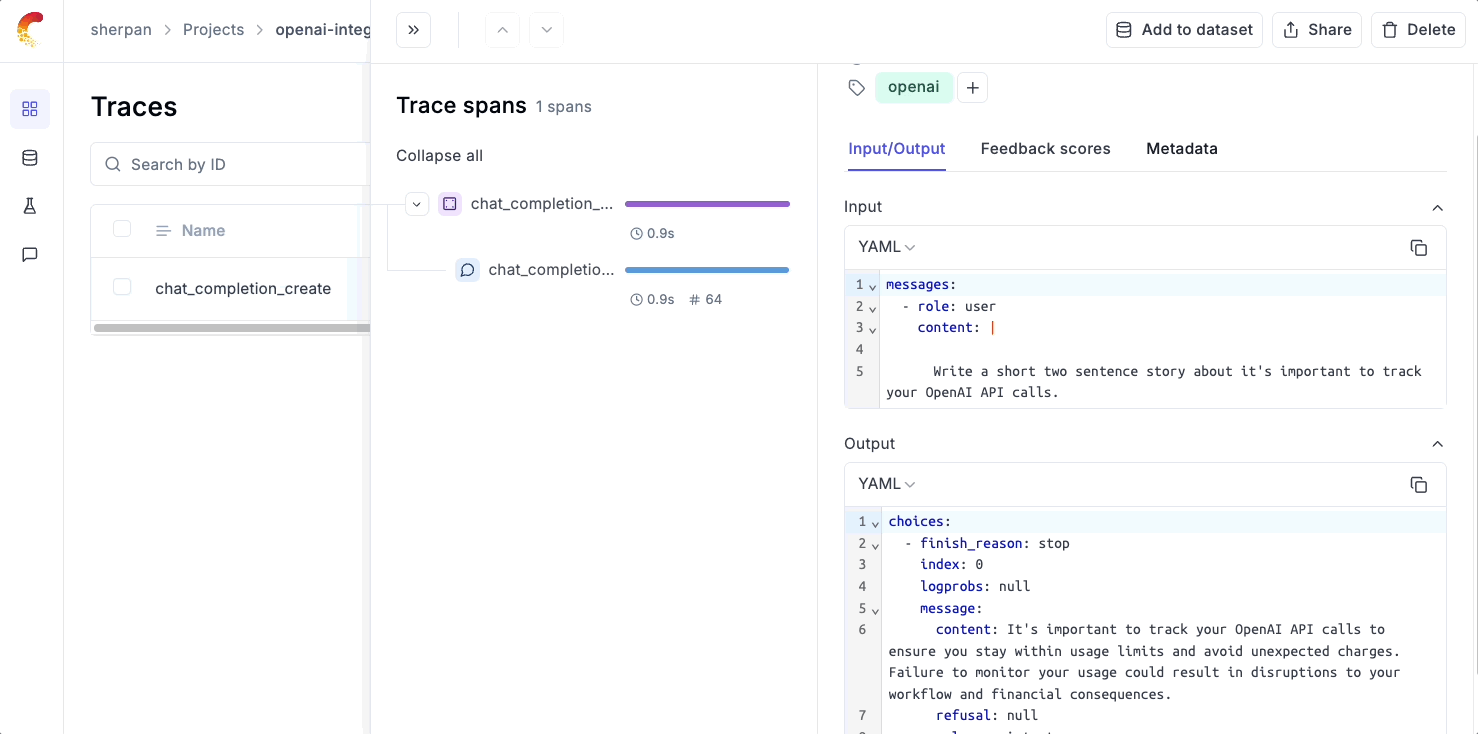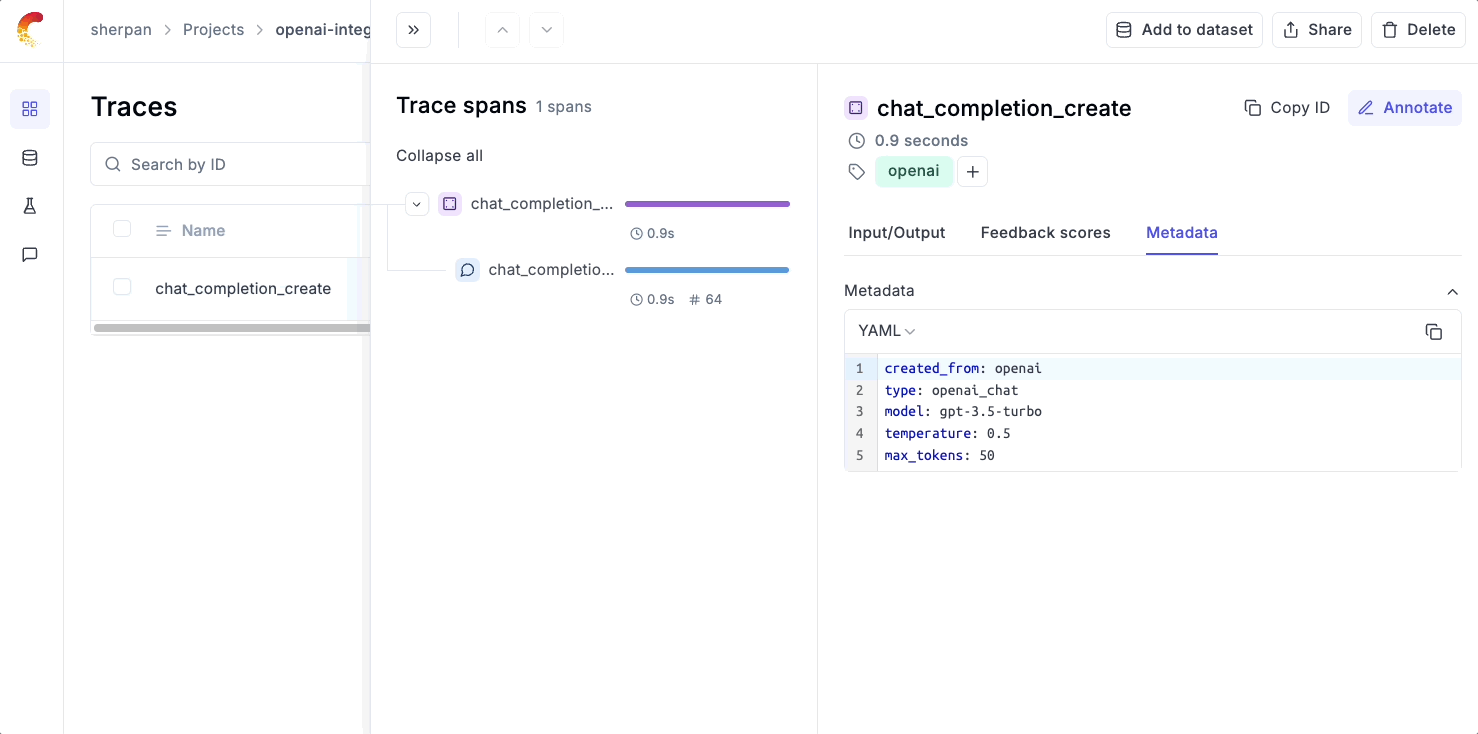
Multi-Call Logging
For some applications, developers rely on a series of calls to OpenAI to get the appropriate response. For these use cases, we recommend using the track decorator function as shown below.
This will enable users to log multiple spans within a single trace, making it easier to debug a multi-step process.
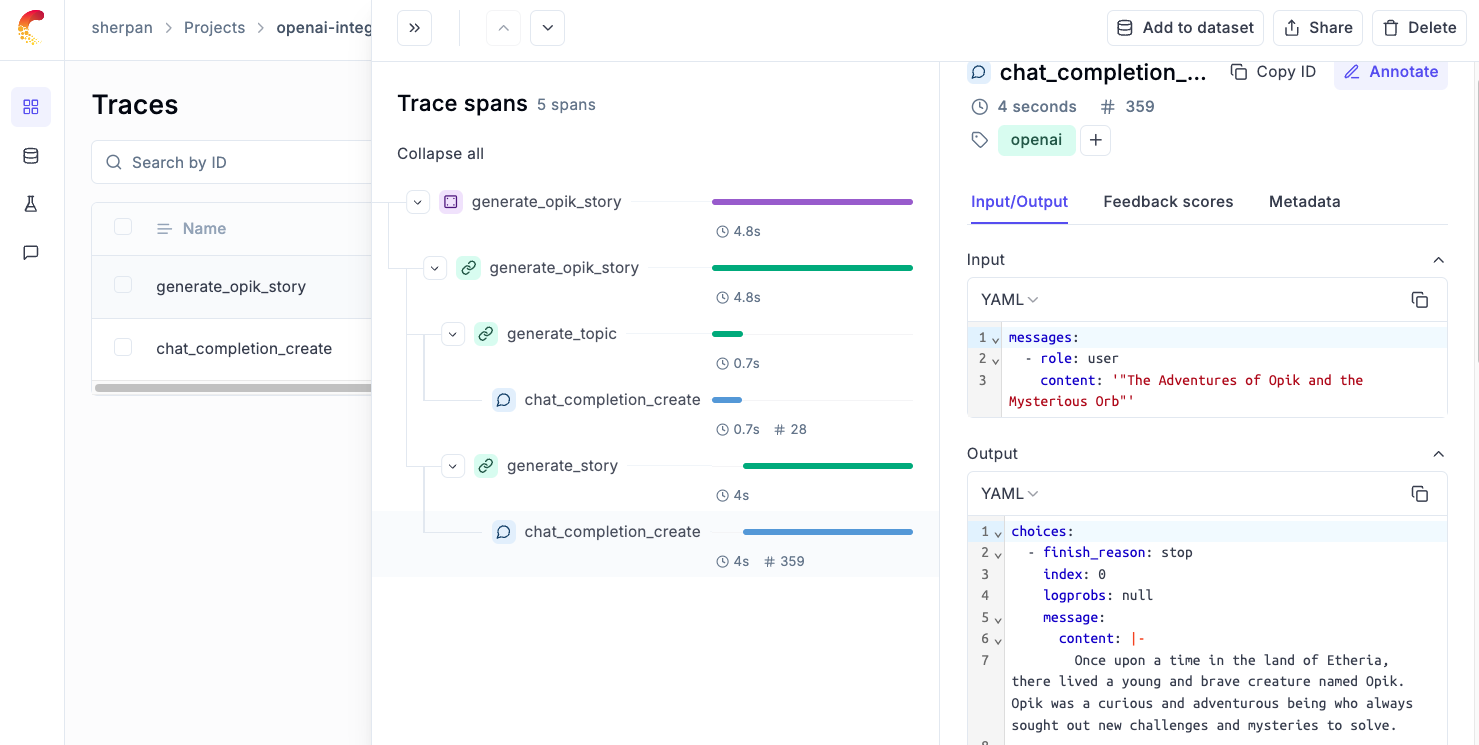
Evaluating Responses from OpenAI
Whether you want to manually annotate LLM responses or run an automated evaluation experiment, Opik can serve as your single source of truth for all your OpenAI evals.
Manual Annotation
With Opik, you can score any trace or span logged to the platform. Users can define their own feedback metrics (numerical) or (categorical) and come up with their own bespoke scoring mechanism.
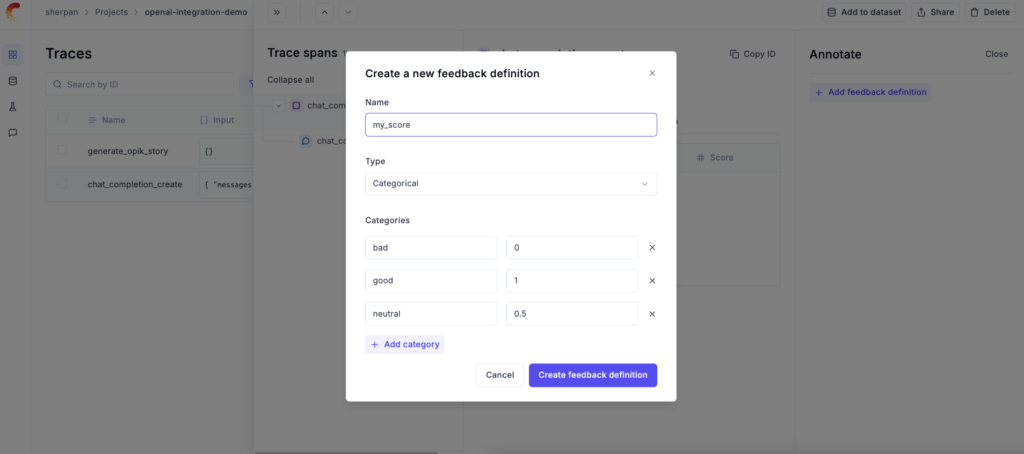
Automated OpenAI Evals
Opik has out-of-box evaluation metrics that developers can use to automatically score their LLM responses. These metrics are grouped into two categories: heuristic metrics and LLM-as-a-judge metrics.
To run an eval, a user needs to define a dataset filled with sample LLM inputs and their expected responses. Datasets can be populated in 3 different ways:
-
-
- Via the Opik SDK
- Manually within the Opik UI
- You can add previously logged traces to a dataset
-
Below is a code snippet that creates a dataset of Spanish sentences and their English translations.
Next, we will evaluate our Spanish-to-English translation app using the Levenshtein Metric. Here is now we define our evaluation experiment with Opik:
Heading to Opik, we can see at a high level how our OpenAI model performed on our eval test and can than drill down on individual samples which the model didn’t perform well on.
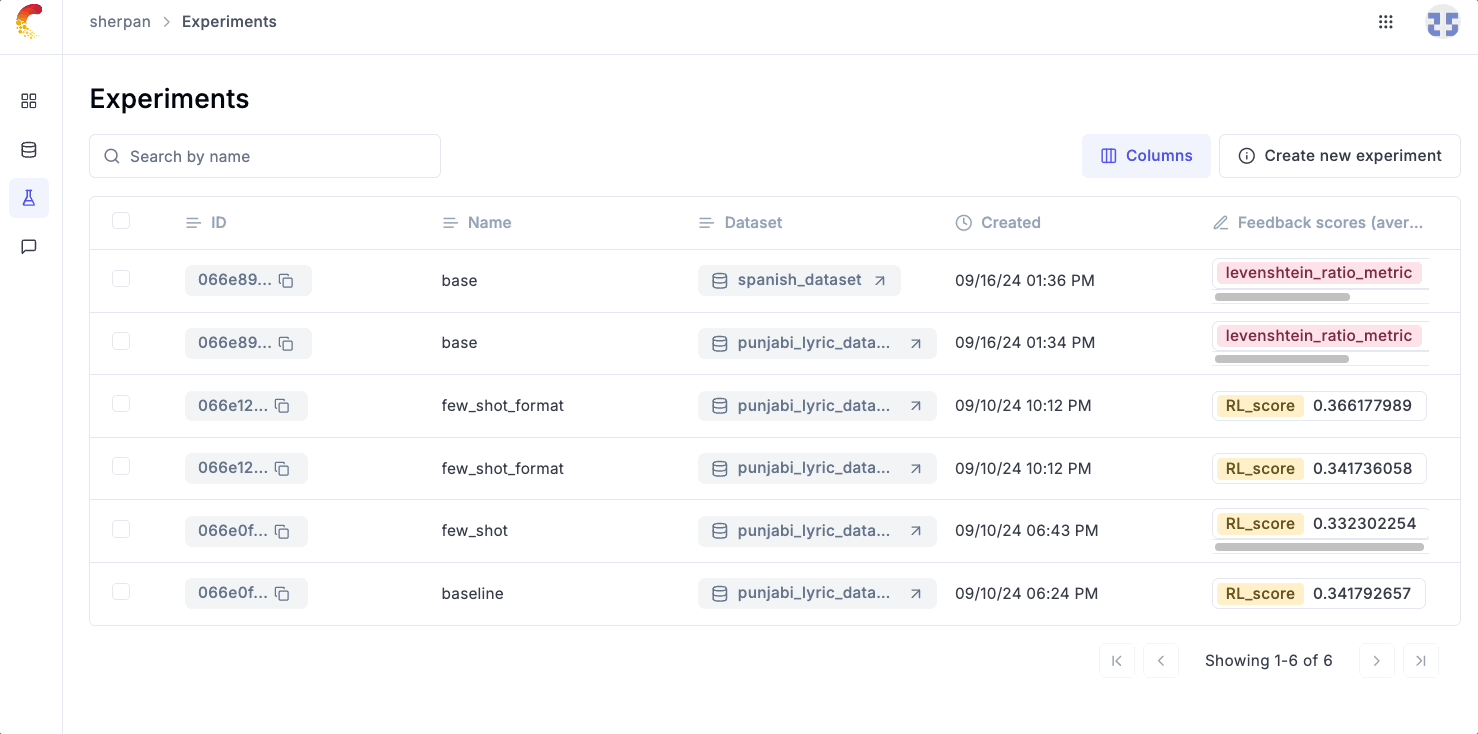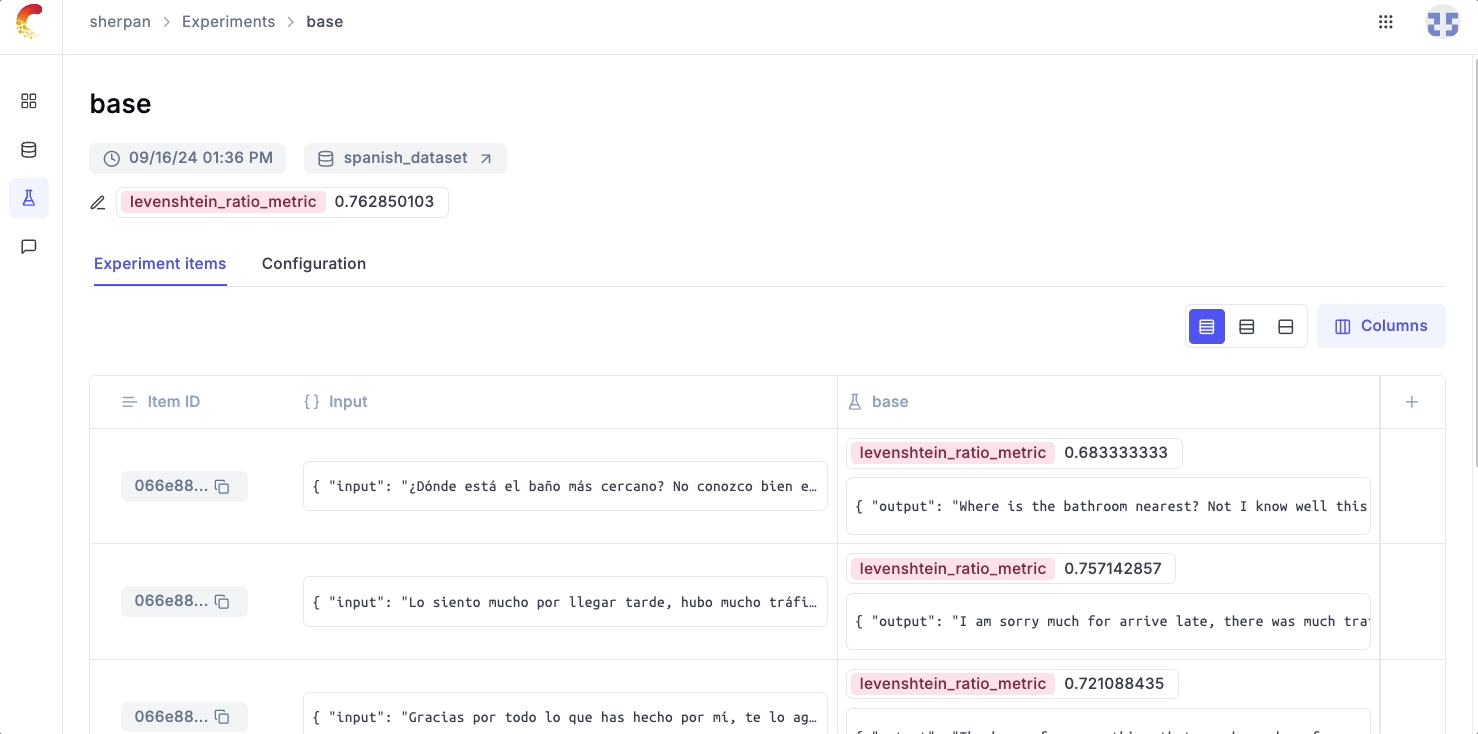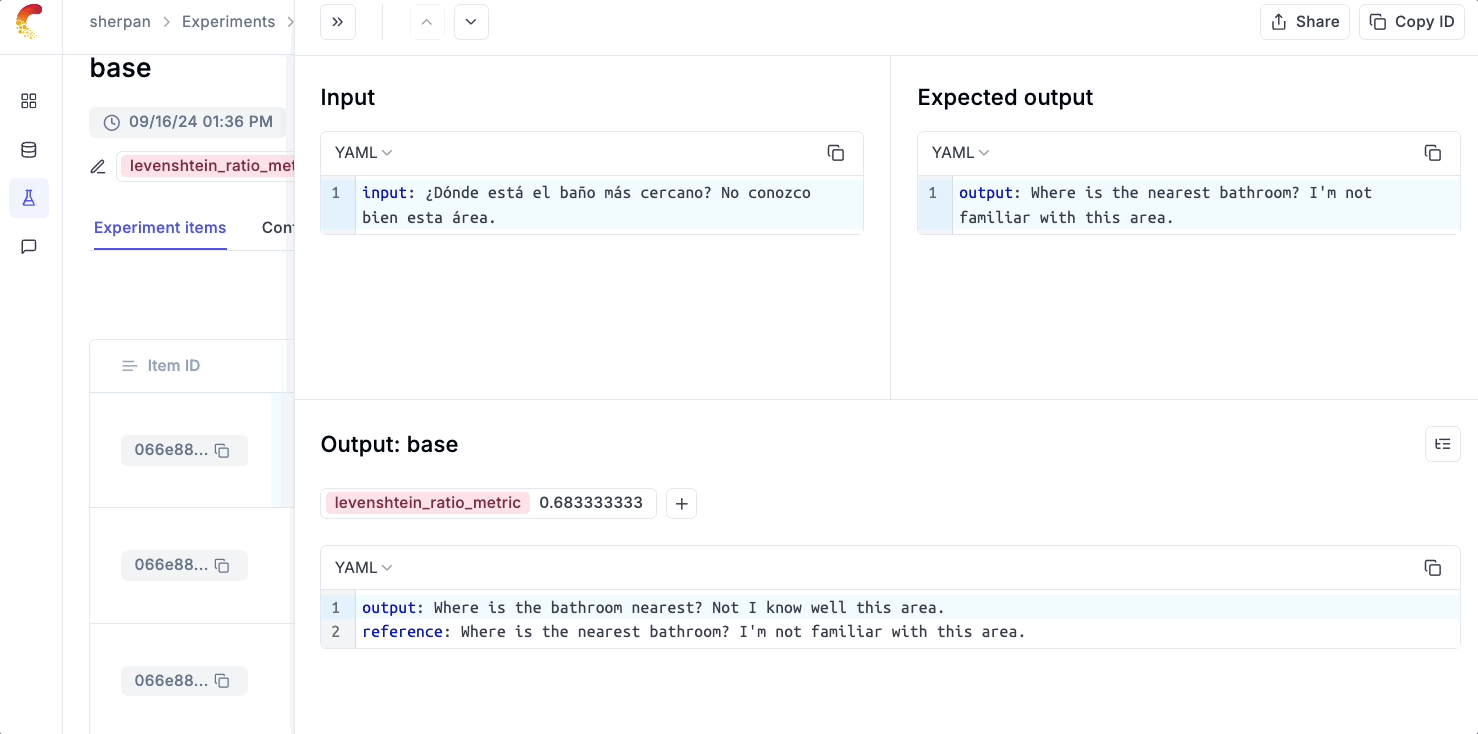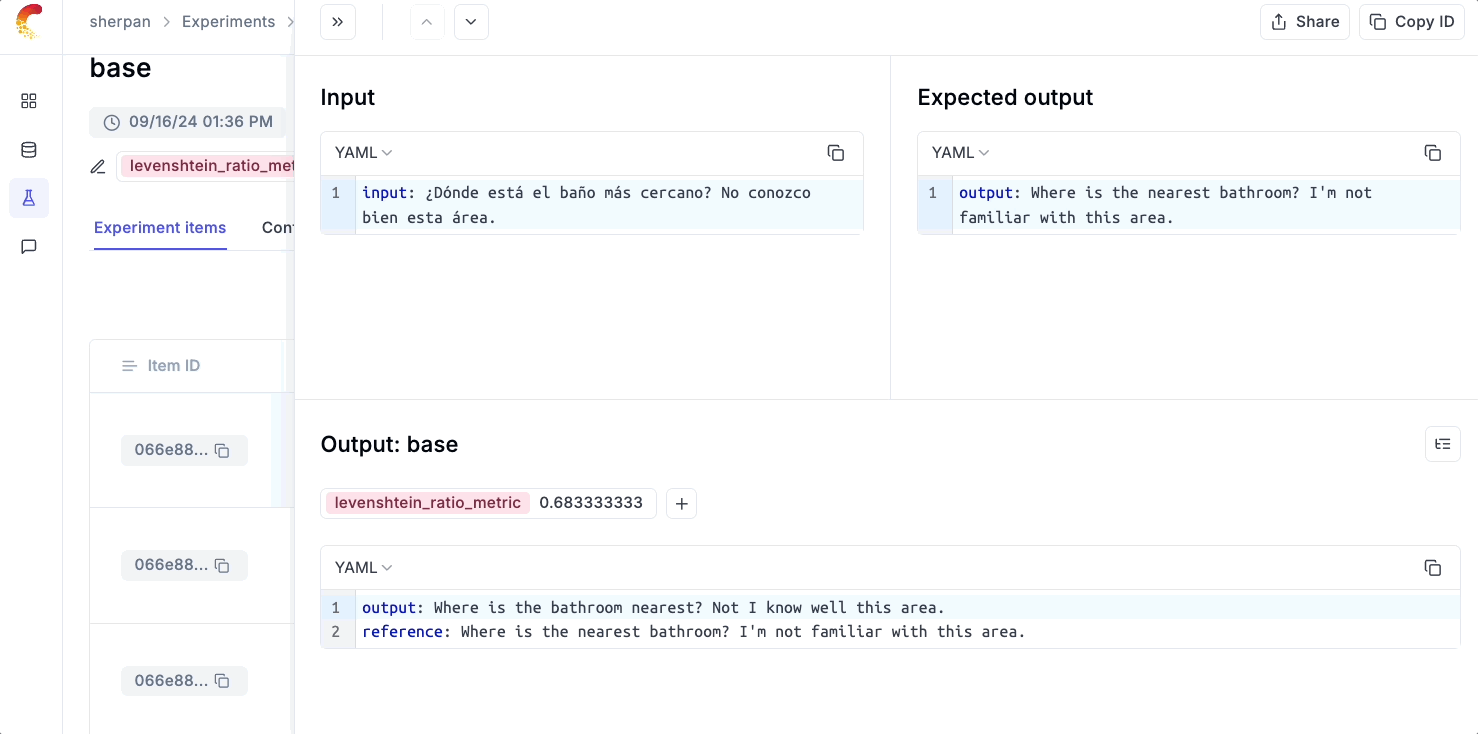
💡 As we iterate on our app with better prompts or by trying out different models, the Opik evals UI makes it easy to quickly see whether we are better or worse from what we tried previously.
Get Started with Opik Today
It’s quick and easy to add Opik to your current OpenAI-powered workflows and start logging and iterating to improve the LLM responses returned to your app. To try the hosted version of Opik, sign up free here. And if you find this open-source project useful, we’d appreciate a star on GitHub. Feel free to give us any feedback you might have on the issues tab.
Related Articles


