G-Eval for LLM Evaluation
LLM-as-a-judge evaluators have gained widespread adoption due to their flexibility, scalability, and close alignment with human judgment. They excel at tasks that are difficult to quantify and evaluate with traditional heuristic metrics like hallucination detection, creative generation, content moderation, and logical reasoning.
Yet, while they may seem simple on the surface, implementing them can prove very challenging. Evaluating a model across multiple metrics often requires creating separate LLM-as-a-Judge pipelines for each metric and combining their outputs. G-Eval simplifies this process by consolidating evaluations into a single metric, effectively providing the model with a unified scorecard.
Compared with other LLM-as-a-judge evaluators, G-Eval stands out for its ease-of-use and adaptability.
So, how does G-Eval work?
G-Eval is composed of three main components: the prompt, automatic CoT reasoning, and the scoring function. The user only defines the input prompt, which consists of the “Task Introduction” and “Evaluation Criteria.” These are then fed into an LLM which generates detailed “Evaluation Steps” using Chain-of-Thought reasoning. The LLM uses these automatically-generated steps, along with the original user-defined prompt, to evaluate the NLG outputs and format them in a form-filling pattern. Finally, a scoring function is applied.

In this article, you’ll learn more about each of these components as we walk through a step-by-step example. Let’s dive in!
Evaluating GPT-4o Summarizations With G-Eval
A major advantage of G-Eval is its versatility. The initial user-defined input prompt can be customized for almost any NLG use case, including text summarization, dialogue generation, and machine translation.
For this tutorial, we’ll be using G-Eval to score how well OpenAI’s GPT-4o summarizes news articles from the SummEval dataset, hosted by Hugging Face, the same dataset used in the original G-Eval paper.
We’ll first take a subset of this dataset to walk through the core components of G-Eval and how to implement them with Opik. Once we’ve gotten a grasp on the basics, we’ll use the full SummEval dataset to benchmark our customized G-Eval evaluation tasks and criterion against human-annotated scores and calculate the Spearman coefficient.
1. Prompt for NLG Evaluation
G-Eval supports a wide range of NLG tasks, making it crucial to clearly define the evaluation objective for the specific task at hand. The initial prompt is the only user-defined input to G-Eval in most out-of-the-box implementations of the metric, including Opik’s. This prompt is a natural language instruction that defines:
• the evaluation task (task_introduction)
• the evaluation criteria (evaluation_criteria)
For general-purpose scenarios, we might provide broad instructions, such as:
TASK_INTRODUCTION = "You are an expert judge tasked with evaluating the faithfulness of an AI-generated answer to the given context."
Alternatively, for specialized use cases, we can craft more tailored instructions, ensuring the model understands the task clearly and doesn’t stray off topic. For example:
TASK_INTRODUCTION = """
You will be given one summary written for a news article.
Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
"""
The initial prompt should also include evaluation criteria for the model to use. This may be as simple as ensuring that the model does not hallucinate or introduce new information:
EVALUATION_CRITERIA = "In provided text the OUTPUT must not introduce new information beyond what's provided in the CONTEXT."
Or, we may want the model to focus on more specific aspects of the output, such as coherence, conciseness, relevance, fluency, or grammar. We may also define the scoring system we wish the model to use. For example:
COHERENCE_EVALUATION_CRITERIA = """
Coherence (1-5) - the collective quality of all sentences.
We align this dimension with the DUC quality question of structure and coherence whereby "the summary should be well-structured and well-organized.
The summary should not just be a heap of related information, but should build from sentence to a coherent body of information about a topic.
"""
As the only user-defined input to G-Eval, you’ll spend most of your time optimizing these two variables. This will most likely be an iterative process, as we’ll explore later on in this article.
2. Auto Chain-of-Thought for NLG Evaluation
Traditionally, Chain-of-Thought (CoT) is a prompting technique where reasoning steps are explicitly broken down in sequence to improve the problem-solving and decision-making of an AI. It can significantly improve LLM outputs, but can be a costly and tedious manual task.
Fortunately, most modern large language models are capable of automating this process by generating the reasoning steps on their own when prompted to do so. Auto CoT not only gives G-Eval a more robust reasoning process (leading to higher quality outputs), but also makes G-Eval more scalable than manual approaches.
This step is especially useful for complex evaluation tasks that require more than one step, or for evaluations with multiple dependencies. An example of auto CoT reasoning steps might look something like this:
Step 1: Identify the key information in the question.
Step 2: Verify if the AI-generated response directly answers the question.
Step 3: Confirm the correctness of the answer; Paris is indeed the capital of France.
Step 4: Verify that no new information has been introduced in the AI-generated response.
Note that these steps are generated automatically by the model and are not input by the user.
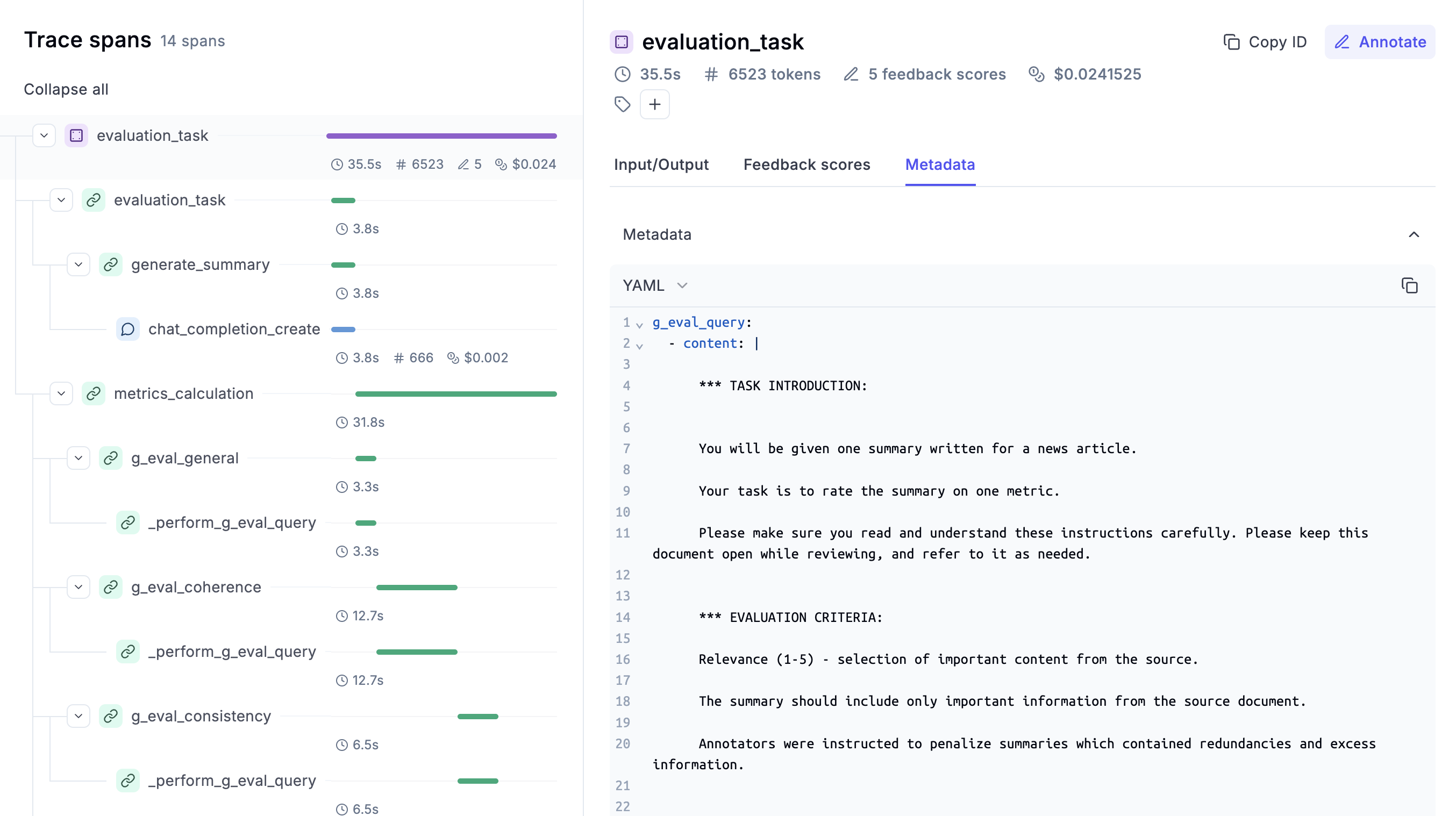
3. Scoring Function
The user-defined task introduction and evaluation criteria, along with the auto-generated CoT reasoning steps, are now concatenated with the original context and target text and the result is passed to the scoring function. The scoring function calls the evaluating LLM, which is prompted to output a score using a form-filling paradigm. The resulting input might look like the following example from the original G-Eval paper:
You will be given one summary written for a news article.
Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
Relevance (1-5) - selection of important content from the source. The summary should include only important information from the source document. Annotators were instructed to penalize summaries which contained redundancies and excess information.
Evaluation Steps:
1. Read the summary and the source document carefully.
2. Compare the summary to the source document and identify the main points of the article.
3. Assess how well the summary covers the main points of the article, and how much irrelevant or redundant information it contains.
4. Assign a relevance score from 1 to 5.
Example:
Source Text:
{{Document}}
Summary:
{{Summary}}
Evaluation Form (scores ONLY):
- Relevance:
The scoring function then normalizes the scores using the probabilities of the output tokens and takes their weighted sum. This is done to:
- Prevent low variance in LLM output scores, which occurs for some evaluation tasks.
- Obtain more fine-grained, continuous scores, as LLMs will often only output integer scores, even when prompted to do otherwise.

This is done automatically in Opik, but you can check out the source code here if you’d like to see how it’s implemented.
G-Eval With Opik
Now that you’re familiar with the core components of G-Eval, let’s implement it in Opik! If you aren’t already, feel free to follow along with the full-code Colab tutorial here. For more information, check out the docs here.
In our first example, we’ll take a subset of the SummEval dataset and use OpenAI’s GPT-4o to generate summaries of the articles. We’ll then use G-Eval to evaluate the quality of those summaries, starting off with a simple, generic set of evaluation criteria, and then venturing into some more specific criterion and comparing the results.
We start off by defining our model, system prompt, and the application function we’ll call to generate the summaries:
import openai
MODEL = "gpt-4o"
SYSTEM_PROMPT = "Generate a concise summarization of the article you are provided with by the user."
# Define the LLM application with tracking
def generate_summary(input: str) -> str:
response = openai_client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": input},
],
)
return {"summary": response.choices[0].message.content}
We also define our evaluation task, in which we return a dictionary containing the exact variables needed to calculate the evaluation score.
def evaluation_task(data):
llm_output = generate_summary(data['text'])
return {"context": data['text'], "output": llm_output}
We’ll then instantiate Opik’s built-in G-Eval metric and specify the task_introduction and evaluation_criteria. First, we’ll create a general G-Eval metric, followed by some that specifically look at aspects like coherence, relevance, fluency, and consistency.
TASK_INTRODUCTION = "You are an expert judge tasked with evaluating the faithfulness of an AI-generated answer to the given context."
EVALUATION_CRITERIA = "In provided text the OUTPUT must not introduce new information beyond what's provided in the CONTEXT."
g_eval_general = GEval(
task_introduction=TASK_INTRODUCTION,
evaluation_criteria=EVALUATION_CRITERIA,
name="g_eval_general"
)
SUMMEVAL_TASK_INTRODUCTION = """
You will be given one summary written for a news article.
Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
"""
COHERENCE_EVALUATION_CRITERIA = """
Coherence (1-5) - the collective quality of all sentences.
We align this dimension with the DUC quality question of structure and coherence whereby "the summary should be well-structured and well-organized.
The summary should not just be a heap of related information, but should build from sentence to a coherent body of information about a topic."""
g_eval_coherence = GEval(
task_introduction=SUMMEVAL_TASK_INTRODUCTION,
evaluation_criteria=COHERENCE_EVALUATION_CRITERIA,
name="g_eval_coherence"
)
CONSISTENCY_EVALUATION_CRITERIA = """
Consistency (1-5) - the factual alignment between the summary and the summarized source.
A factually consistent summary contains only statements that are entailed by the source document.
Annotators were also asked to penalize summaries that contained hallucinated facts.
"""
g_eval_consistency = GEval(
task_introduction=SUMMEVAL_TASK_INTRODUCTION,
evaluation_criteria=CONSISTENCY_EVALUATION_CRITERIA,
name="g_eval_consistency"
)
FLUENCY_EVALUATION_CRITERIA = """
Fluency (1-3): the quality of the summary in terms of grammar, spelling, punctuation, word choice, and sentence structure.
- 1: Poor. The summary has many errors that make it hard to understand or sound unnatural.
- 2: Fair. The summary has some errors that affect the clarity or smoothness of the text, but the main points are still comprehensible.
- 3: Good. The summary has few or no errors and is easy to read and follow.
"""
g_eval_fluency = GEval(
task_introduction=SUMMEVAL_TASK_INTRODUCTION,
evaluation_criteria=FLUENCY_EVALUATION_CRITERIA,
name="g_eval_fluency"
)
RELEVANCE_EVALUATION_CRITERIA = """
Relevance (1-5) - selection of important content from the source.
The summary should include only important information from the source document.
Annotators were instructed to penalize summaries which contained redundancies and excess information.
"""
g_eval_relevance = GEval(
task_introduction=SUMMEVAL_TASK_INTRODUCTION,
evaluation_criteria=RELEVANCE_EVALUATION_CRITERIA,
name="g_eval_relevance"
)
We can then use the evaluate function to run the LLM application and evaluation task defined above, and apply each of the G-Eval metrics we defined, passed as a list to the scoring_metrics parameter.
from opik.evaluation import evaluate
# Perform the evaluation
evaluation = evaluate(
experiment_name="My G-Eval Experiment",
dataset=dataset,
task=evaluation_task,
scoring_metrics=[g_eval_general,
g_eval_coherence,
g_eval_consistency,
g_eval_fluency,
g_eval_relevance],
experiment_config={
"model": MODEL,
"system_prompt": SYSTEM_PROMPT,
}
)

scoring_metrics parameter of the evaluate function, Opik automatically calculates each evaluation metric for each sample and aggregates them across the full dataset.Evaluating Our Evaluation
In this next section we’ll try to answer the question, “how good are our evaluations, anyways?”
Luckily, the SummEval dataset also provides human annotations or “ground truth labels”, which we can use to evaluate how closely our G-Eval scores align with human judgment (the gold standard for most LLM tasks).
We’ll be using a slightly different subset of the dataset than in the first example, so we aren’t exactly comparing apples to apples here. Importantly, however, we’ll be using the same user inputs (task introductions and evaluation criterion). This means we’ll be able to tweak our prompts and measure a corresponding quantifiable difference in output quality.
For full details on how we created this second subset of the dataset, check out the Colab here.
Once we have our dataset, the only thing we need to change from the previous workflow is the evaluation task. Here we return a dictionary including the context and LLM outputs. We won’t need to define an LLM application step, as the dataset already has LLM-generated summaries.
from opik.evaluation import evaluate
def evaluation_task(data):
return {"context": data['text'], "output": data["machine_summaries"]}
# Perform the evaluation
evaluation = evaluate(
experiment_name="My G-Eval Experiment",
dataset=dataset,
task=evaluation_task,
scoring_metrics=[g_eval_coherence,
g_eval_consistency,
g_eval_fluency,
g_eval_relevance],
project_name="g-eval-demo-correlations"
)
The evaluate function calculates and logs each of the G-Eval metrics listed in the scoring_metrics parameter. To fetch these scores so that we can calculate the Spearman correlation coefficient on them, we’ll use the search_traces method of the Opik client.
traces = client.search_traces(project_name="g-eval-demo-correlations", max_results=1000000) # some number greater than total results
Once we have our trace and experiment information locally, we’ll isolate the feedback scores:
# Gather relevance scores
g_eval_relevance_list = [
score.value
for trace in traces
for score in trace.feedback_scores
if score.name == "g_eval_relevance"
]
And finally, we can calculate the correlation between the human-annotated scores and those generated from our G-Eval metrics:
How close were you able to get to the results reported in the original G-Eval paper?

G-Eval Performance and Concerns
But, why use an LLM as an evaluator at all? After all, LLMs are near-complete black boxes and require far more computational overhead than heuristic, or even learned, evaluation metrics.
Firstly, using an LLM as an evaluator bypasses the need for a reference or “ground truth” text, which is particularly problematic when dealing with natural language tasks that often have multiple valid outputs due to paraphrasing, synonyms, contextual nuance, and semantic ambiguity. These restrictions could lead to biased evaluations or overfitting. Ground truth labels are not only less flexible, though, they’re also extremely expensive themselves to acquire, which can limit the scalability of an application.
Prior to G-Eval, other reference-free LLM-based evaluators like GPTScore were used especially for tasks that require creativity, diversity, or complex contextual understanding. These evaluators showed marked improvement over heuristic metrics, but they generally had much lower human correspondence than even medium-sized neural network evaluators.
G-Eval improved upon the performance of previous LLM-based evaluators like GPTScore and more closely aligned with human judgment than most existing metrics. It is scalable and consistent, and highly adaptable to various NLG tasks.
As with all LLM-based metrics, however, it is important to remember that it inherits biases and limitations from the underlying LLM, which may impact fairness or accuracy. It is also more computationally expensive than most heuristic metrics and far less interpretable.
If you found this article useful, follow me on LinkedIn and Twitter for more content!
Related Articles

